Ghostwriting-Service Dr. Rainer Hastedt
R-Grafiken - einfache Beispiele
Scatterplots für große Datensätze
Pie-Charts, 3D-Grafiken, Kalenderplots
Grafiken zur Korrelationsanalyse
Histogramme und Kernel-Densities
Diagnoseplots zur Regressionsanalyse
Multiple Mittelwert- oder Medianvergleiche
Diagnoseplots für multivariate Daten
Diagramme zur Hauptkomponentenanalyse
Ich habe alle auf dieser Seite gezeigten Grafiken anhand von R-Skripten erzeugt.
Im folgenden Beispiel (Kernel-Density zum Datensatz LakeHuron) sehen Sie, wie ich den Hintergrund der Grafik und die Beschriftung der y-Achse geändert habe:
library(KernSmooth)
library(ggplot2)
x <- LakeHuron
kd <- bkde(x)
daten <- data.frame(xa=kd$x, ya=kd$y)
png("rgrafik010a.png", width=390, height=260, bg="transparent")
ggplot(data=daten, aes(x=xa, y=ya)) +
geom_path() +
theme_bw() +
theme(plot.background = element_rect(colour=NA, fill="transparent")) +
ggtitle("Kernel-Density") +
xlab("") +
scale_y_continuous("", breaks=c(0,0.1,0.2,0.3), labels=c("0,0", "0,1", "0,2", "0,3"))
dev.off()Sie können R-Grafiken auch in druckreifer Qualität speichern, insbesondere als TIFF-Dateien mit 300 dpi, als Postscript-Dateien (EPS) und als Windows Metafiles (EMF).
Eine nachträgliche Bearbeitung mit Adobe Illustrator oder Inkscape ist ebenfalls möglich (gilt für die Formate PDF, EPS, SVG und EMF).
Scatterplots für große Datensätze
Die folgende Grafik zeigt einen Scatterplot mit 52.000 Datenpunkten, von denen viele übereinander oder eng nebeneinander liegen:
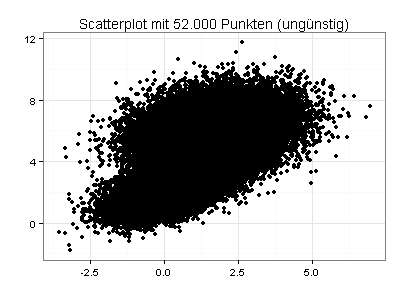
Sie sehen jetzt den gleichen Scatterplot mit transparenten und stark verkleinerten Datenpunkten. Die Daten haben demnach zwei Schwerpunkte:
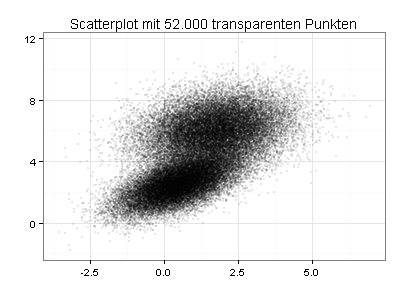
Ich kann beide Schwerpunkte auch verdeutlichen, indem ich in den ursprünglichen Scatterplot Konturlinien einzeichne oder meine Daten als farbig gefüllte 2D-Dichtefunktion darstelle:
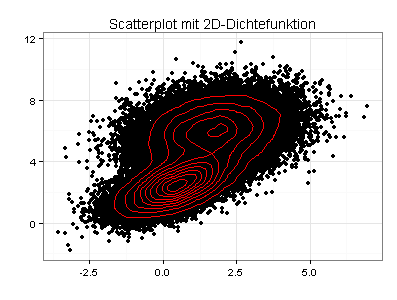
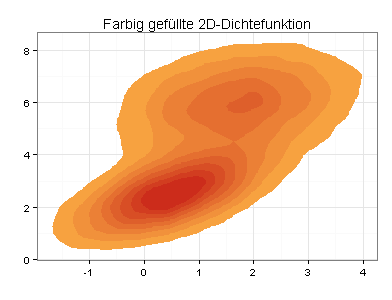
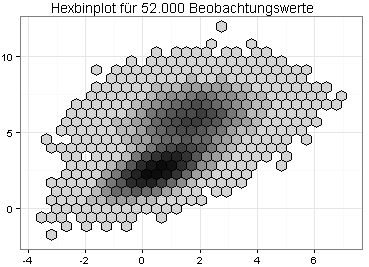
Eine 2D-Dichtefunktion kann unansehnlich sein, wenn die zu plottenden Daten ungünstig verteilt sind. Eine interessante Alternative ist daher ein Hexbinplot:
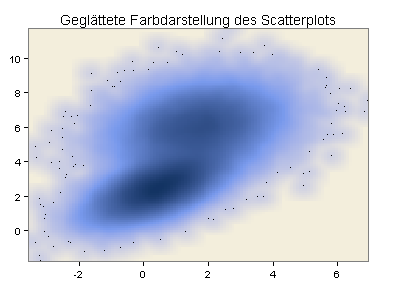
Eine weitere Möglichkeit besteht in einer geglätteten Farbdarstellung des obigen Scatterplots:
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Kreuztabellen als Grafiken
Die folgenden vier Diagramme habe ich mit dem Package Lattice erstellt, das zur Grundversion von R gehört. Lattice ist besonders gut geeignet, wenn Sie Likert-Skalen plotten wollen.
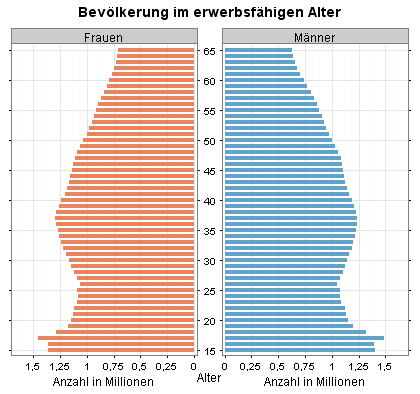
Meine erste Lattice-Grafik (Alterspyramide) besteht aus zwei Panels. Die Achsenbeschriftungen zwischen den beiden Panels wurden von Lattice ausgerichtet.
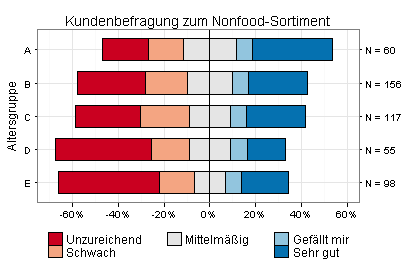
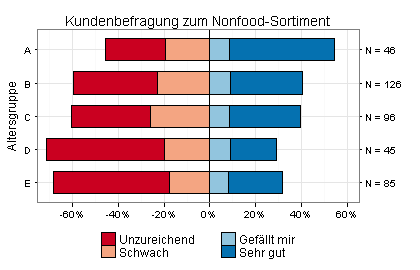
Das nächste Balkendiagramm zeigt Ergebnisse einer Kundenbefragung zum Nonfood-Sortiment eines großen Supermarkts, differenziert nach fünf Altersgruppen:
Ich habe jetzt alle Befragungsteilnehmer ausgeklammert, die das Nonfood-Sortiment des Supermarkts mittelmäßig finden. Wegen dieser änderung können Sie sehr leicht sehen, dass das Nonfood-Sortiment von den Befragten der Altersgruppen B bis E überwiegend als unzureichend oder schwach eingestuft wird:
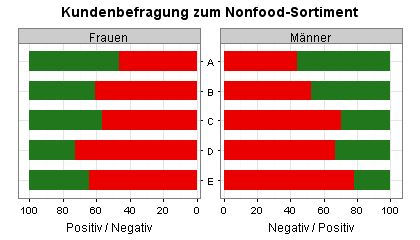
Für die nächste Grafik (eine Variante der obigen Alterspyramide) habe ich vier Antwortmöglichkeiten zusammengefasst - Unzureichend und Schwach zu Negativ sowie Gefällt mir und Sehr gut zu Positiv. Mit dieser vereinfachten Einteilung habe ich die Daten für Frauen und Männer separat ausgewertet.
Sie sehen jetzt, dass sich die Befragungsergebnisse (Prozentwerte) der Frauen und Männer in allen fünf Altersgruppen nur wenig unterscheiden:
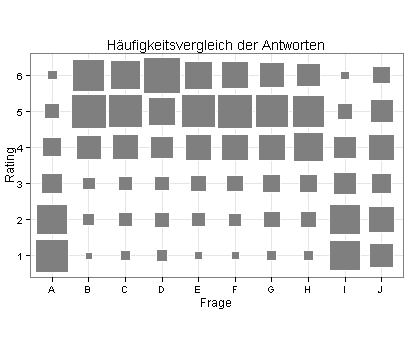
Bei einer anderen Befragung haben die Teilnehmer zehn Fragen (A bis J) jeweils auf einer Rating-Skala von 1 bis 6 beantwortet. Die folgenden vier Diagramme zeigen die Ergebnisse.
Im ersten Diagramm symbolisiert die Größe der grauen Rechtecke die Häufigkeiten:
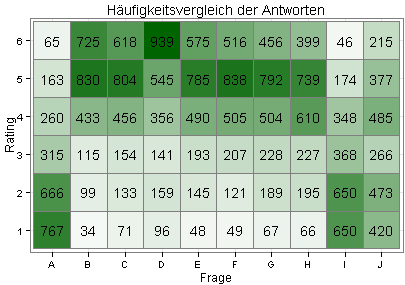
Im zweiten Diagramm (Heatmap) sind die Grüntöne nach der Häufigkeit abgestuft:
Im dritten Diagramm sind die Spalten der Heatmap separat geplottet:
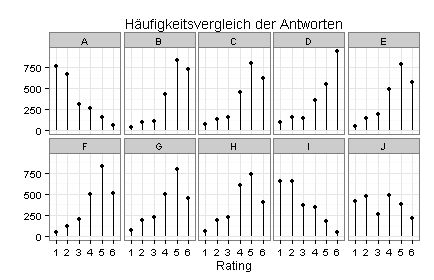
Im vierten Diagramm sind die Zeilen der Heatmap separat geplottet:
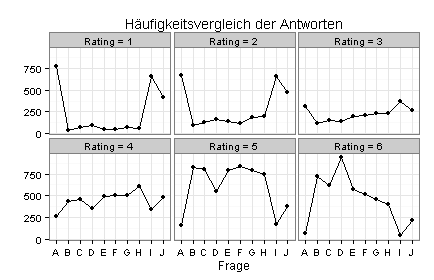
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Pie-Charts, 3D-Grafiken, Kalenderplots
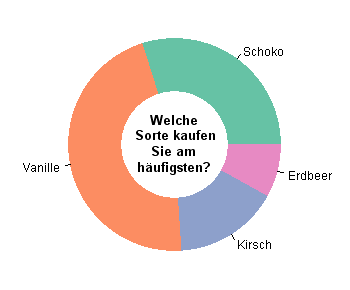
Konventionelle Pie-Charts sind eine gute Alternative zu Balkendiagrammen, wenn die relative Größe der geplotteten Segmente leicht erkennbar ist. Sie sehen zum Beispiel im folgenden Pie-Chart auf Anhieb, dass Kirsch einen höheren Anteil hat als Erdbeer.
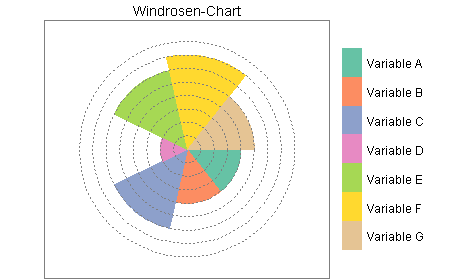
Windrosen-Charts sind Barplots mit Polarkoordinaten. Die x-Achse läuft hier nicht waagerecht von links nach rechts, sondern im Uhrzeigersinn von drei Uhr bis drei Uhr:
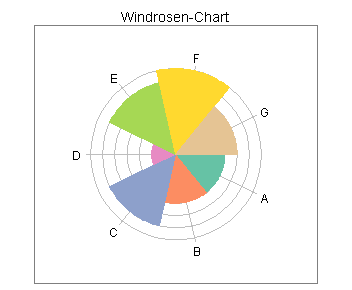
Der gleiche Plot mit Gridlinien im Vordergrund und Legende:
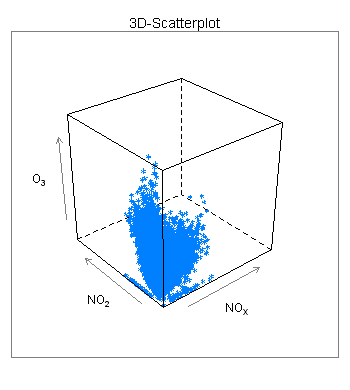
3D-Grafiken sind ungünstig, wenn Sie die genaue Lage von Punkten im dreidimensionalen Raum visualisieren wollen. Sie wollen zum Beispiel verdeutlichen, bei welchen Messwerten für Stickstoff und Stickoxide der Ozongehalt am höchsten ist.
Mit dem folgenden 3D-Scatterplot klappt dies nicht:
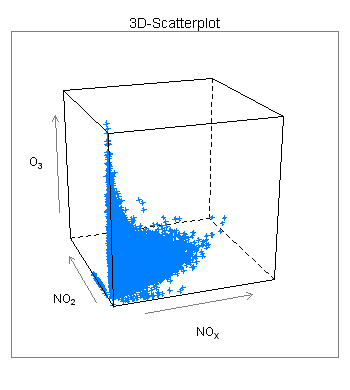
Sie können die Perspektive auch ändern (den Würfel rotieren). Das Ergebnis bleibt trotzdem unbefriedigend:
Eine meiner Ansicht nach bessere Lösung sehen Sie im folgenden Diagramm, das ich mit einer modifizierten Form der scatterPlot-Funktion aus dem openair-Package erstellt habe (meine Beispieldaten stammen ebenfalls von dort):
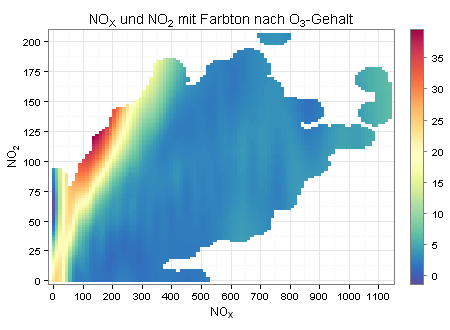
Für das obige Diagramm wurden auf der x-Achse die Messwerte für Stickoxide dargestellt und auf der y-Achse die Messwerte für Stickstoff. Der sich auf diese Weise ergebende Scatterplot wurde dann geglättet und nach den Messwerten für die Ozonkonzentration eingefärbt.
Aus dem openair-Package stammt auch die für das folgende Diagramm verwendete calendarPlot-Funktion. Sie sehen im hiermit erzeugten Kalenderplot, wie sich der Tageswert für den durchschnittlichen Ozongehalt der Luft im Laufe des Jahres 2003 verändert hat:
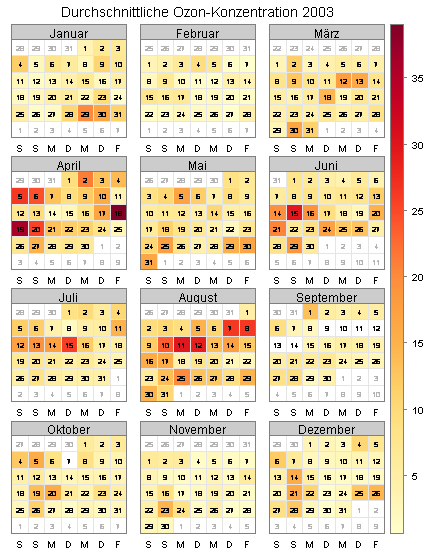
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Grafiken zur Korrelationsanalyse
Im linken Teil des folgenden Diagramms sehen Sie, dass die eingezeichnete Regressionsgerade gut zu den Daten passt. Sie können daher einen linearen Zusammenhang zwischen den beiden Variablen unterstellen. Im rechten Teil des Diagramms sehen Sie die Boxplots der beiden Variablen. Die Variable x = Einfachheit hat demnach eine schiefe Verteilung mit zwei Ausreißern.
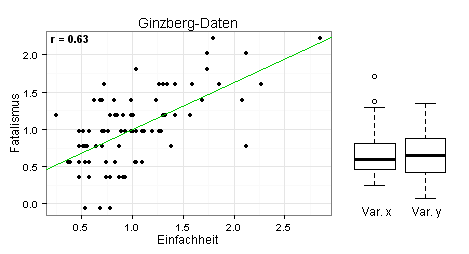
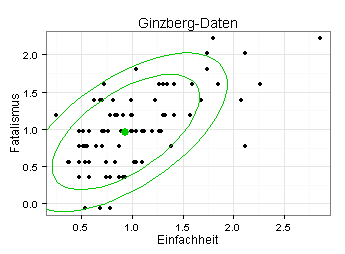
Im nächsten Diagramm sehen Sie neben den Datenpunkten die Mittelwerte der beiden Variablen (grüner Punkt) sowie eine 0,80-Konfidenzellipse und eine 0,95-Konfidenzellipse, jeweils unter der Annahme, dass die zwei Variablen bivariat normalverteilt sind.
Ich untersuche jetzt, ob zwischen zwei Variablen aus einem anderen Datensatz ein linearer Zusammenhang besteht. Ich habe hierzu eine GAM-Linie in meinen Scatterplot eingezeichnet (GAM = Generalized Additive Model).
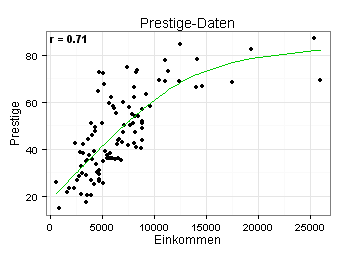
Die GAM-Linie spricht für einen nichtlinearen Zusammenhang. Der angegebene Korrelationskoeffizient (r = 0,71) ist daher wenig aussagekräftig. Weiteres zu diesem Thema finden Sie in meinem Blogbeitrag Korrelationsanalysen bitte mit Vorsicht genießen.
Für die im vorletzten und drittletzten Diagramm verwendeten Daten (r = 0,63) wäre die GAM-Linie eine Gerade, was die Annahme eines linearen Zusammenhangs untermauern würde.
Korrelationsmatrizen bieten einen überblick über Datensätze mit mehr als zwei Variablen. Ich zeige hier zwei Darstellungsformen, die für Datensätze mit bis zu zehn Variablen geeignet sind.
In der ersten Korrelationsmatrix sehen Sie oberhalb der Diagonale die Scatterplots aller möglichen Variablenpaare und unterhalb der Diagonale die zugehörigen Korrelationskoeffizienten in Form von Pie-Charts:
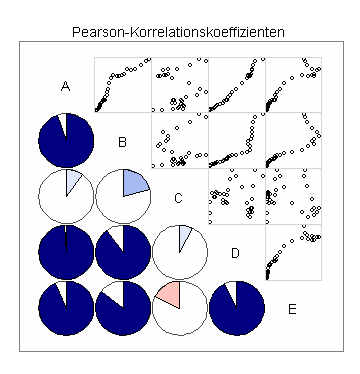
In der zweiten Korrelationsmatrix sehen Sie anstelle der Scatterplots Ellipsen mit gleitenden Durchschnittswerten nach dem Loess-Verfahren:

Zurück zum Seitenanfang
Zur Seite Statistik-Service
Landkarten
Ich werde jetzt Daten des Statistischen Bundesamts zum verfügbaren Pro-Kopf-Einkommen als Landkarten darstellen.
Meine Einkommensdaten haben die folgende Form:
| 2009 | 09 | Bayern | 251471511 | 20111 |
| 2009 | 10 | Saarland | 19230032 | 18743 |
| 2009 | 11 | Berlin | 54412879 | 15843 |
Für meine erste Landkarte unterteile ich die Werte des verfügbaren Pro-Kopf-Einkommens (rechte Spalte) in sechs Intervalle, und zwar so, dass in jedes Intervall möglichst gleich viele Werte fallen. Bei 16 Bundesländern ergeben sich somit zwei bis drei Bundesländer pro Intervall:
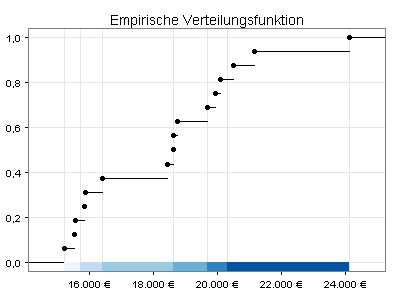
Mit dieser Einteilung erhalte ich die folgende Deutschlandkarte:
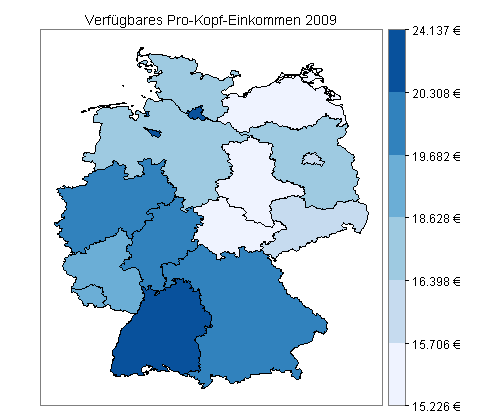
Quellen: Bundesamt für Kartographie und Geodäsie, Frankfurt am Main, 2012 (Shapefiles), Statistisches Bundesamt, Wiesbaden, 2012 (Einkommensdaten).
Für meine zweite Landkarte verwende ich Daten zum verfügbaren Pro-Kopf-Einkommen auf Kreisebene. Ich berechne die Grenzen der sechs Intervalle neu und plotte die Landkarte mit den hierzu passenden Shapefiles:
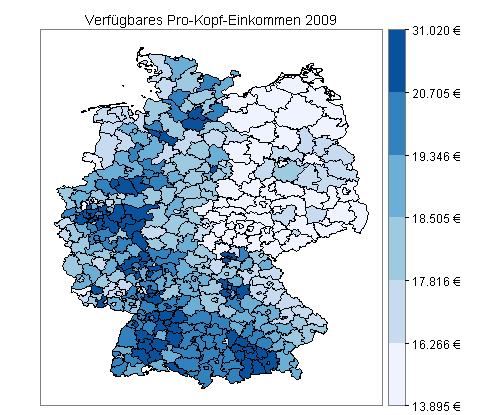
Quellen: Bundesamt für Kartographie und Geodäsie, Frankfurt am Main, 2012 (Shapefiles), Statistisches Bundesamt, Wiesbaden, 2012 (Einkommensdaten).
Für meine dritte Landkarte habe ich zusätzlich die Top 3 des Jahres 2009 ermittelt:
- Heilbronn, kreisfreie Stadt (31.020 €)
- Landkreis Starnberg (29.104 €)
- Hochtaunuskreis (28.242 €)
Ich habe die Koordinaten von Heilbronn und den Kreisstädten Starnberg und Bad Homburg vor der Höhe mit der Funktion geocode() aus dem R-Package ggmap von Google Maps abgerufen und als rote Punkte in meine dritte Landkarte eingetragen:

Quellen: Bundesamt für Kartographie und Geodäsie, Frankfurt am Main, 2012 (Shapefiles), Statistisches Bundesamt, Wiesbaden, 2012 (Einkommensdaten), Google Maps, 2012 (Koordinaten der Top 3).
Die bisherige Klasseneinteilung liefert im Fall von sechs Gruppen für die höchste Einkommenskategorie eine sehr breite Spanne (20.705-31.020). Zum Vergleich habe ich daher die Intervallgrenzen nach der Fisher-Jenks-Methode berechnet, die darauf abzielt, möglichst homogene Gruppen zu bilden:
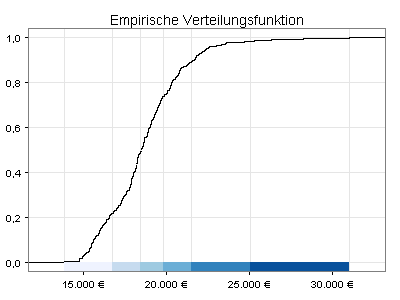
Sie sehen jetzt meine Daten mit der neuen Klasseneinteilung. Als Hintergrund dient ein Ausschnitt aus einer Weltkarte von Natural Earth, den ich als Graustufenbild dargestellt habe:
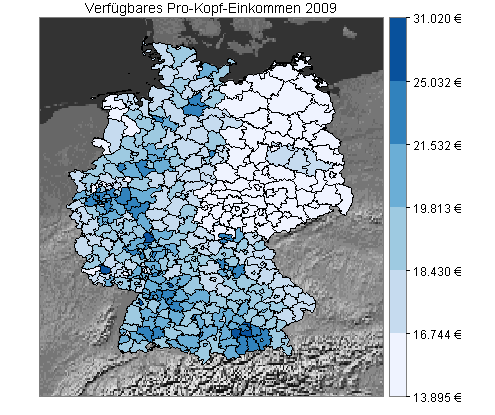
Quellen: Bundesamt für Kartographie und Geodäsie, Frankfurt am Main, 2012 (Shapefiles), Statistisches Bundesamt, Wiesbaden, 2012 (Einkommensdaten), Natural Earth, 2013 (Gray Earth with Shaded Relief and Hypsography).
Die folgende Landkarte basiert auf drei Datensätzen von Natural Earth: Umrisslinien aller Kontinente, Grenzen aller Länder und Koordinaten ausgewählter Flughäfen.
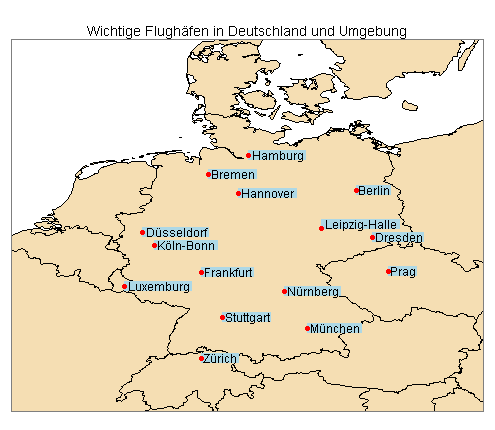
Quellen: Natural Earth, 2013 (Shapefiles), Google Maps, 2013 (Koordinaten der Flughäfen Leipzig-Halle und Hannover-Langenhagen).
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Zeitreihenanalyse
Finanzdaten
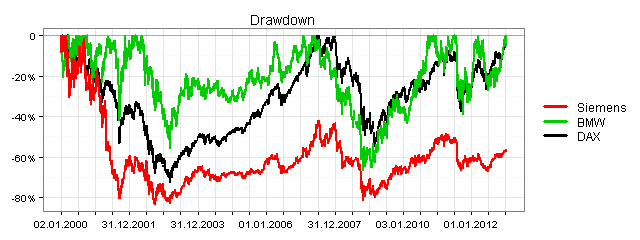
Sie können bei Yahoo Finance verfügbare Zeitreihen mit der Funktion getSymbols() aus dem Package quantmod in R einlesen. Als Beispiele dazu sehen sehen Sie in den folgenden drei Grafiken jeweils die Xetra-Schlusskurse für alle Börsentage in der Zeit vom 2. Januar 2000 bis zum 9. Januar 2013:
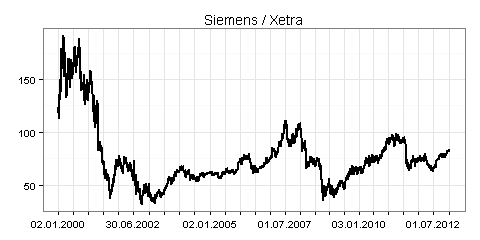
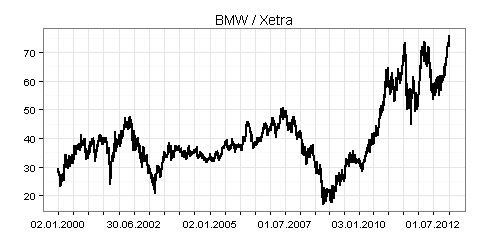
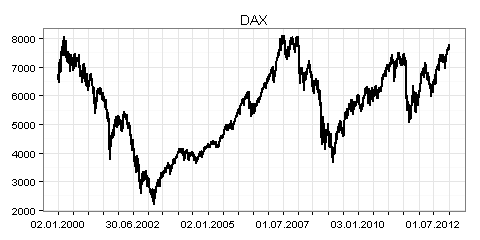
Der Return bezeichnet in diesem Zusammenhang die prozentuale Veränderung des Schlusskurses zum vorherigen Börsentag. Beträgt zum Beispiel der Schlusskurs heute 100 Euro und morgen 107 Euro, so ergibt sich ein Return in Höhe von 7 Prozent.
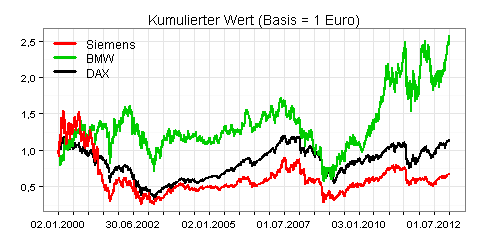
Sie können anhand dieser Kennzahl berechnen, wie sich der Kurswert von Aktien im Zeitablauf entwickelt. Zum Beispiel werden aus einem Euro bei einem Return in Höhe von -8 Prozent 0,92 Euro und aus den 0,92 Euro bei einem Return von 10 Prozent 1,012 Euro.
Der Drawdown kann auf unterschiedliche Weise berechnet werden. Die hier verwendete Methode erkennen Sie anhand der folgenden Tabelle und der zugehörigen Drawdown-Grafik:
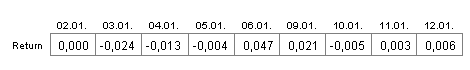
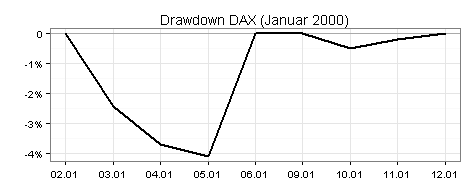
Jetzt die komplette Grafik:
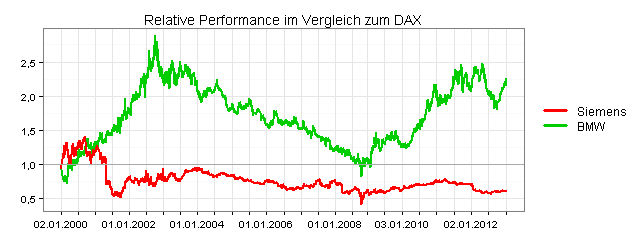
In der folgenden Grafik sehen Sie die relative Performance von Siemens und BMW, jeweils auf Basis der Return-Werte:
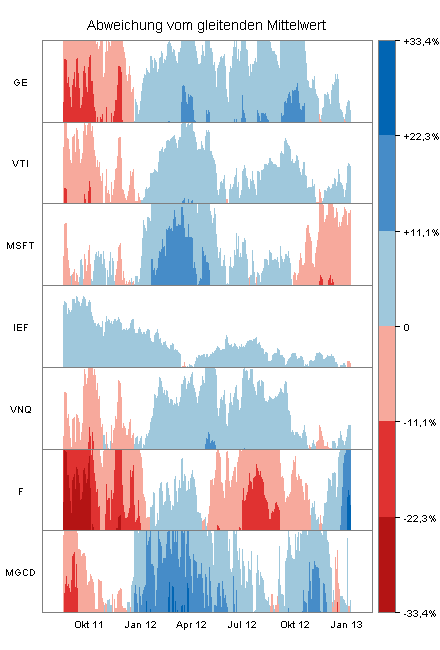
Der folgende Horizonplot zeigt die Abweichung der Schlusskurse vom gleitenden Durchschnitt für sieben Unternehmen in der Zeit vom 15. August 2011 bis zum 9. Januar 2013 (Kursdaten von Yahoo Finance, Zeitfenster für den gleitenden Durchschnitt jeweils 200 Börsentage).
Die folgenden drei Diagramme verdeutlichen anhand der ersten Zeitreihe, wie Horizonplots konstruiert sind:
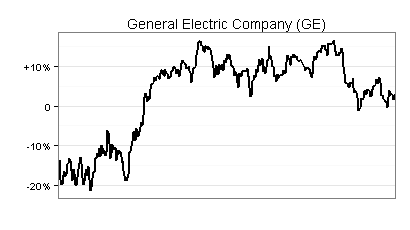
Das Liniendiagramm wird jetzt als Fläche dargestellt, wobei immer die Oberkante maßgeblich ist. Rot steht für negative Werte und Blau für positive Werte. Negative Werte sind demnach mit ihrem Absolutbetrag angesetzt (zum Beispiel -10% als +10%).
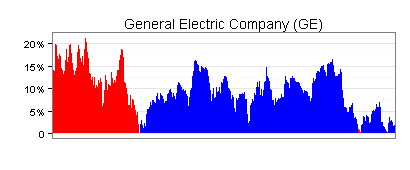
Im nächsten Schritt teile ich die über der x-Achse liegende Fläche horizontal in zwei Abschnitte. Im unteren Abschnitt mache ich aus Rot Orange und aus Blau Hellblau. Dann verschiebe ich den oberen Abschnitt nach unten zur x-Achse.
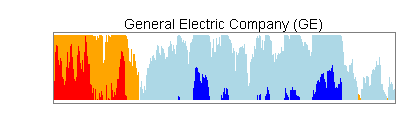
Sie sehen jetzt anhand der Farben, an welchen Stellen hohe positive, moderat positive, hohe negative und moderat negative Werte auftreten.
Im obigen Horizonplot ist die Einteilung feiner. Sie sehen dies an der Farbskala auf der rechten Seite, der Sie auch die Wertebereiche entnehmen können.
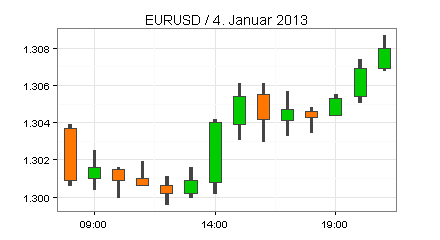
Der folgende Candle Chart beschreibt die Entwicklung des Wechselkurses EURUSD am 4 . Januar 2013 von 8 bis 21 Uhr. Basis sind Daten von FXHISTORICALDATA.COM, die Sie mit der Systematic Investor Toolbox in R einlesen können.
Zeitreihenprognose
Sie sehen im folgenden Diagramm meine Ausgangsdaten, die monatliche Absatzmenge für ein Produkt im Zeitraum von Januar 2002 bis einschließlich Oktober 2011. Ich habe die Zeitreihe auf zwei Panels verteilt, damit das Balkendiagramm nicht zu breit wird.
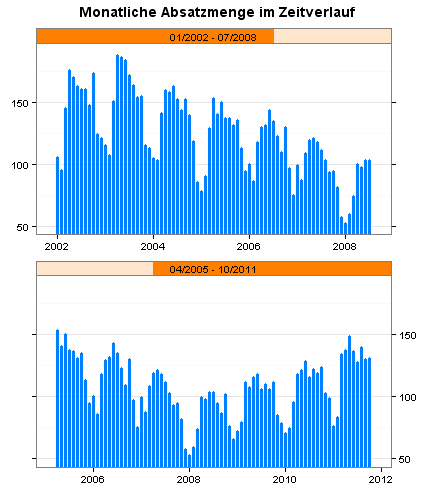
Ich werde anhand der Daten für Januar 2002 bis einschließlich Oktober 2009 die Absatzmengen für die folgenden 24 Monate prognostizieren und mit den tatsächlichen Werten vergleichen.
1. Ansatzpunkt:
Meine Absatzdaten zeigen starke Saisonschwankungen. Ich zerlege daher meine Zeitreihe mit dem STL-Verfahren (Seasonal Decomposition of Time Series by Loess):
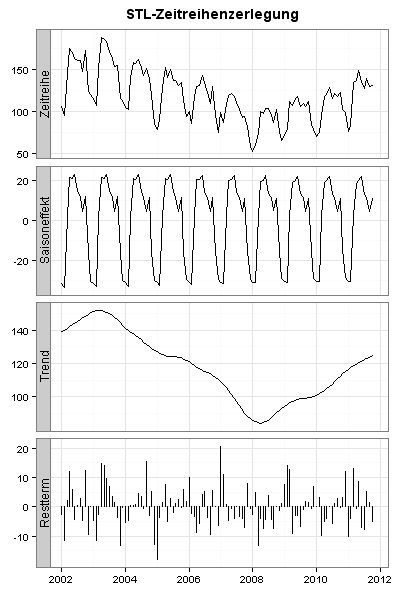
Sie sehen im folgenden Diagramm die Trendkomponente zusammen mit meinen grau gezeichneten Ausgangsdaten:
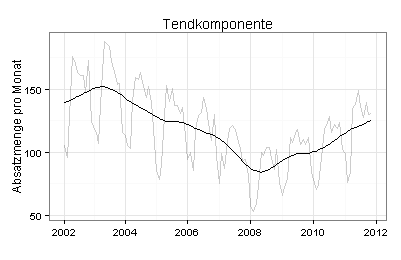
Ich berechne jetzt die Trendkomponente für den Zeitraum von Januar 2002 bis einschließlich Oktober 2009 und prognostiziere auf dieser Basis mit der ETS-Methode die Trendkomponente für die folgenden 24 Monate:
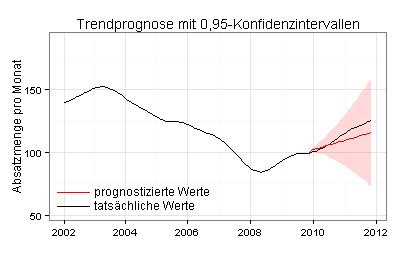
Durch eine vergrößerte Darstellung sehen Sie deutlicher als im vorherigen Diagramm, dass die prognostizierten Trendwerte anfangs höher sind als die tatsächlichen Trendwerte:
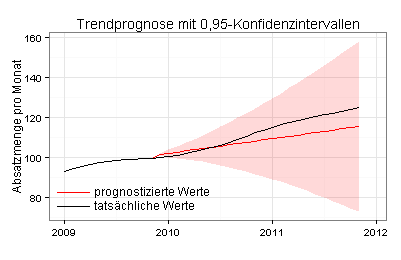
2. Ansatzpunkt:
Ich verwende jetzt die unbereinigten Ausgangsdaten. Auf Basis meiner Daten für den Zeitraum von Januar 2002 bis einschließlich Oktober 2009 prognostiziere ich mit der ETS-Methode die Absatzmengen für die folgenden 24 Monate:
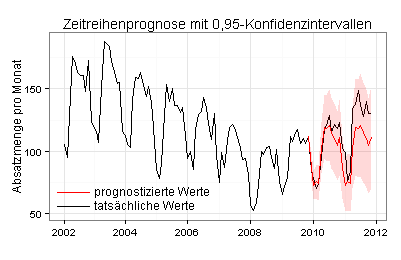
Vergrößerte Darstellung:
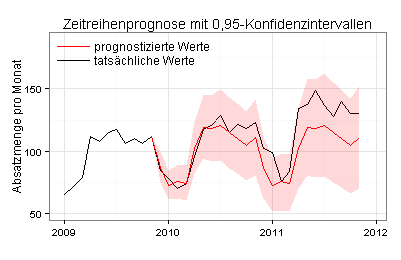
3. Ansatzpunkt:
Ich arbeite mit geglätteten Daten, die ich zum Beispiel mit dem Holt-Winters-Verfahren (exponentielle Glättung) erzeugen kann:
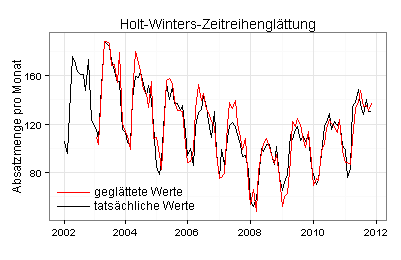
Ich glätte jetzt die unbereinigten Ausgangsdaten für den Zeitraum von Januar 2002 bis einschließlich Oktober 2009 und prognostiziere auf dieser Basis mit der Holt-Winters-Methode die Absatzmengen für die folgenden 24 Monate:
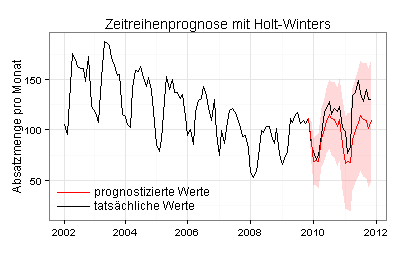
Die 0,95-Konfidenzintervalle sind jetzt zum Teil deutlich breiter als mit der ETS-Methode.
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Mehrere Hypothesentests
Binomialtest
Ein herkömmliches Produktionsverfahren liefert erfahrungsgemäß in 83 von 100 Fällen einwandfreie Ergebnisse. Dies ist die als blaue Linie eingezeichnete Benchmark (Wert gemäß Nullhypothese).
Das Balkendiagramm zeigt, dass ein neues Verfahren bei einem ersten Test eine Erfolgsquote von 85 Prozent gebracht hat. Können wir hierin eine signifikante Verbesserung sehen?
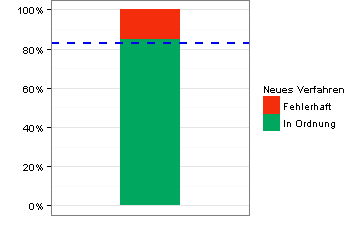
Ein-Stichprobentests für Anteile
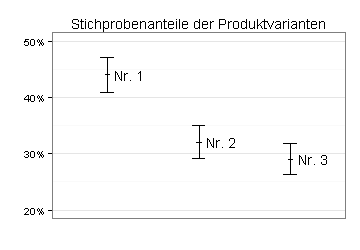
Ein Unternehmen hat drei Varianten eines neuen Produkts getestet. Das Diagramm zeigt die Stichprobenanteile der drei Produktvarianten und die zugehörigen Konfidenzintervalle.
Chi-Quadrat-Unabhängigkeitstest
187 Personen wurden danach gefragt, wie sie Produkt A und B einschätzen. Die Antwortmöglichkeiten waren jeweils »schlecht« (--), »mittelmäßig« (+/-) und »gut« (++).
Der folgende Tile Plot zeigt die Ergebnisse:
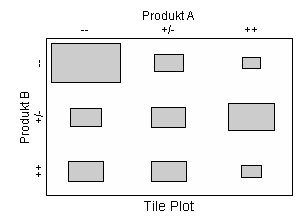
Demnach haben die meisten Befragungsteilnehmer sowohl Produkt A als auch Produkt B mit -- bewertet (Rechteck links oben).
Der folgende Association Plot zeigt das Ergebnis eines Unabhängigkeitstests, den ich mit den obigen Daten durchgeführt habe:
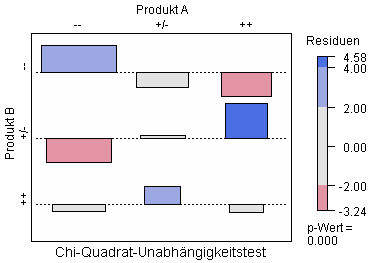
Die Variablen »Bewertung von Produkt A« und »Bewertung von Produkt B« sind demnach nicht voneinander unabhängig (Signifikanzniveau 0,000).
Die im Association Plot dargestellten Residuen legen nahe:
- Wer A schlecht findet, findet B wahrscheinlich schlecht
- Wer A mittelmäßig findet, findet B wahrscheinlich mittelmäßig oder gut
- Wer A gut findet, findet B wahrscheinlich mittelmäßig
Shapiro-Wilk-Test auf Normalverteilung
Sie sehen im folgenden Diagramm die relativen Häufigkeiten der Stichproben-Messwerte, die sich bei einem Experiment ergeben haben (Größe der roten Fläche gleich eins).
Außerdem sehen Sie im Diagramm die Dichtefunktion einer Normalverteilung mit einem Mittelwert in Höhe des Stichproben-Mittelwerts und einer Standardabweichung in Höhe der Stichproben-Standardabweichung:
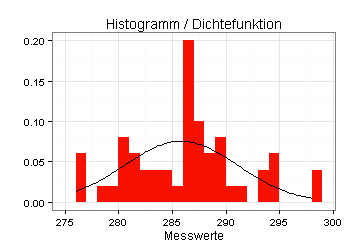
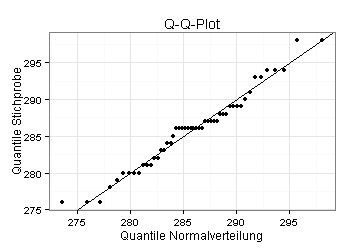
Man könnte aufgrund des obigen Diagramms denken, dass die Messwerte nicht normalverteilt sind. Gemäß Shapiro-Wilk-Test wäre diese Einschätzung jedoch falsch.
Die Messwerte passen in Wirklichkeit sehr gut zur Normalverteilungsannahme:
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Histogramme und Kernel-Densities
Sie sehen im folgenden Histogramm Daten über den Wasserstand des Lake Huron von 1875 bis 1972, die zur Standardinstallation von R gehören.
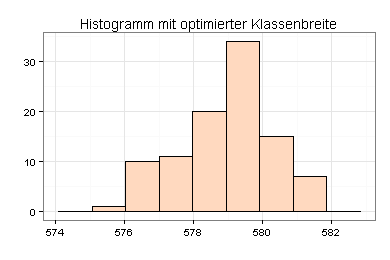
Das Histogramm, das ich ohne Vorgaben zur Klassenbreite erstellt habe, erweckt den Eindruck, dass die Verteilung der Wasserstände schief ist:
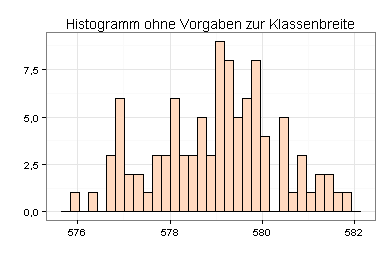
Ich habe die optimale Klassenbreite nach dem Verfahren von M. P. Wand ermittelt und das Histogramm hiermit neu erstellt.
Das Histogramm wirkt jetzt weniger schief:
Ich habe zusätzlich die Kernel-Density ermittelt. Das Ergebnis ähnelt der Glockenkurve einer Normalverteilung:
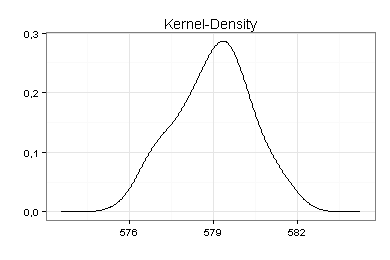
Ein Shapiro-Wilk-Test auf Normalverteilung führt zur gleichen Einschätzung (p=0,327).
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Diagnoseplots zur Regressionsanalyse
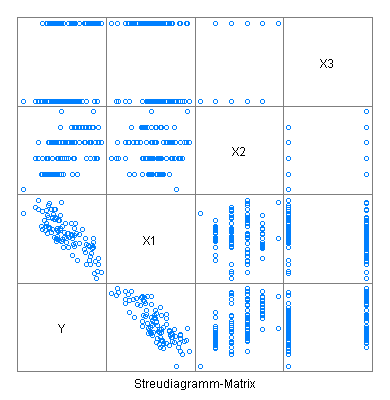
Als Ausgangspunkt dient ein Datensatz mit vier Zeitreihen, den ich zunächst in Form einer Scatterplot-Matrix darstelle.
Hierdurch zeigt sich, dass X1 und Y stark negativ korreliert sind. Außerdem wirken X2 und X3 wie Faktoren.
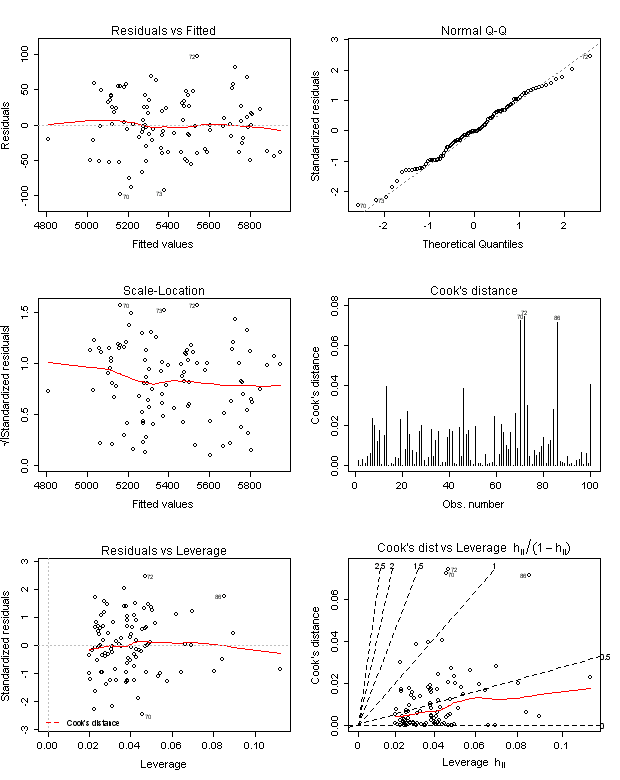
Für meine Regressionsgleichung Y ~ X1+X2+X3 lasse ich mir die zugehörigen Standard-Diagnoseplots ausgeben, die ohne zusätzliche Formatierungen wie folgt aussehen:
Ich erstelle den ersten und den dritten Plot, die beide dem gleichen Zweck dienen, noch einmal:
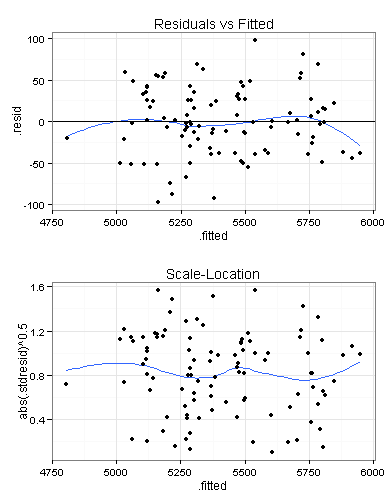
Im oberen Plot sollten die eingezeichneten Punkte gleichmäßig oberhalb und unterhalb der schwarzen Nulllinie liegen, was hier meines Erachtens der Fall ist.
Schlecht wäre dagegen ein klar erkennbarer Trend in den Residuen, zum Beispiel links überwiegend negative Residuen, rechts überwiegend positive oder in einem der beiden Plots eine blaue Linie mit fast an jeder Stelle positiver Steigung.
Sie sehen jetzt eine weitere Variante des ersten Plots (Residuals vs Fitted):
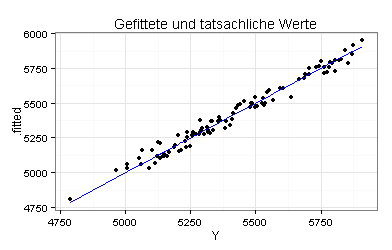
Vorgegeben ist ein Wert auf der horizontalen Achse, zum Beispiel Y = 5.000. Ich suche in meinem Datensatz alle Beobachtungen, für die der Wert der abhängigen Variablen (Y) gleich 5.000 ist. Für diese Beobachtungen berechne ich die Werte meiner Regressionsfunktion (.fitted) und zeichne sie in mein Diagramm, als Punkte an der Stelle Y = 5.000.
Sie sehen hierdurch sehr deutlich, dass die Regressionsgleichung Y ~ X1+X2+X3 die zugrunde liegenden Daten gut beschreibt und dass die Modellannahme der Homoskedastizität für meine Regressionsanalyse plausibel ist.
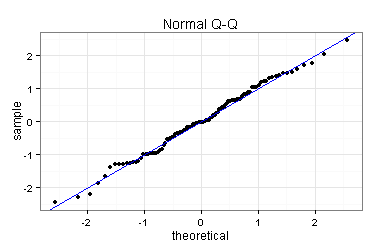
Ich erstelle den zweiten Diagnoseplot (Normal Q-Q) noch einmal. Der Plot deutet darauf hin, dass die Residuen normalverteilt sind.
Für bedeutsam halte ich auch den vierten Diagnoseplot (Cooks-Distanzen), den ich ebenfalls noch einmal erstelle:
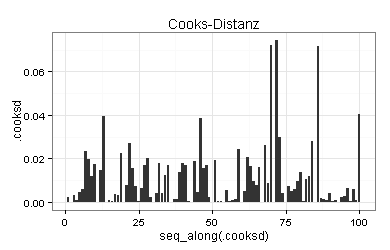
Die Cooks-Distanz ist ein Maß für den Einfluss, den der betreffende Beobachtungswert auf die Schätzergebnisse ausübt.
Ungünstig wäre zum Beispiel ein Datensatz, in dem ein Beobachtungswert eine Cooks-Distanz von 0,5 aufweist und in dem alle übrigen Cooks-Distanzen kleiner als 0,1 sind. Sie hätten dann einen Beobachtungswert, der die Schätzergebnisse wesentlich stärker beeinflusst als alle anderen Beobachtungswerte. In diesem Fall wäre zu prüfen, ob sich die Schätzergebnisse durch das Weglassen dieses Beobachtungswerts deutlich ändern würden.
Für meine Daten sind alle Cooks-Distanzen gering.
Meine Daten sind demnach für eine lineare Regressionsanalyse geeignet. Als nächstes untersuche ich daher mein Modell Y ~ X1+X2+X3.
Sie finden einen Teil der Ergebnisse im folgenden Plot, der die 0,95-Konfidenzintervalle für die standardisierten Regressionskoeffizienten zeigt:
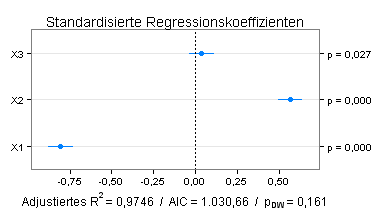
Die Variable X3 hat einen positiven Einfluss auf Y, der aber schwach und statistisch nicht signifikant ist (p=0,027 für den entsprechenden t-Test). Ich prüfe daher das Modell Y ~ X1+X2.
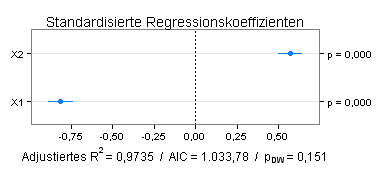
Die Einflüsse der Variablen X1 und X2 sind jetzt ähnlich groß wie im Modell mit drei Variablen. Für beide Modelle kann Autokorrelation verneint werden (Signifikanzniveau für einen zweiseitigen Durbin-Watson-Test jeweils ≥ 0,05).
Nach den Kriterien »adjustiertes Bestimmtheitsmaß« und »Akaike's Information Criterion« (AIC) schneidet das vereinfachte Modell jedoch schlechter ab.
Marginal Model Plots eröffnen eine weitere Möglichkeit, die Modelle Y ~ X1+X2+X3 und Y ~ X1+X2 miteinander zu vergleichen. Marginal Model Plots zeigen wesentlich detaillierter als der obige Plot »Gefittete und tatsächliche Werte«, wie gut das jeweilige Modell die zugrundeliegenden Daten beschreibt.
Ein gutes Modell zeichnet sich dadurch aus, dass die beiden farbigen Linien in jedem der zugehörigen Marginal Model Plots annähernd deckungsgleich sind.
Für meine beiden Modelle ergeben sich die folgenden sieben Marginal Model Plots:
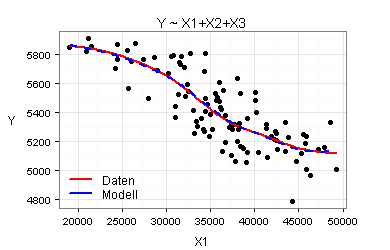
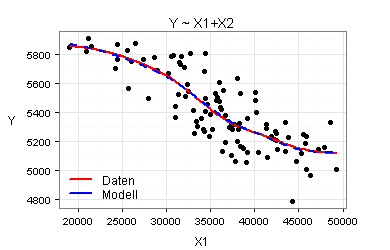

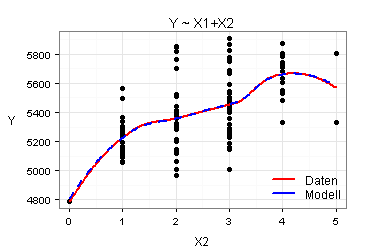
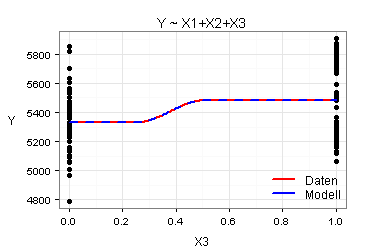
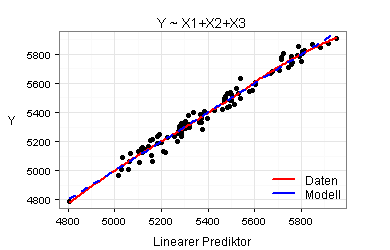
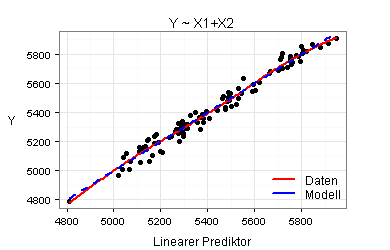
Nach den obigen Marginal Model Plots sind beide Modelle gut. Es kommt daher infrage, mit dem einfacheren Modell zu arbeiten.
Ausführliche Erläuterungen zum Thema »Marginal Model Plots« bieten unter anderem die folgenden beiden Bücher und die dort angegebene Literatur:
- Sanford Weisberg: Applied Linear Regression, 3. Auflage, Hoboken, New Jersey, 2005, Seite 185-191.
- John Fox und Sanford Weisberg: An R Companion to Applied Regression, 2. Auflage, Thousand Oaks, California, 2011, Seite 290-292.
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Multiple Mittelwert- oder Medianvergleiche
Die in diesem Abschnitt gezeigten Grafiken basieren auf dem in R enthaltenen Datensatz chickwts, der das Gewicht von Hühnern zeigt, die unterschiedliche Futterzusätze erhalten haben. Einige Hühner haben zum Beispiel nur den Zusatz casein erhalten, andere nur den Zusatz horsebean.
Sie sehen anhand des ersten Diagramms, dass die Daten für Mittelwertvergleiche zwischen den sechs Gruppen weniger gut geeignet sind. Auffällig sind vor allem die schiefe Verteilung für den Faktor meatmeal, die drei Ausreißer für den Faktor sunflower sowie die geringe Anzahl der Beobachtungswerte (n) für jede der insgesamt sechs Kategorien.
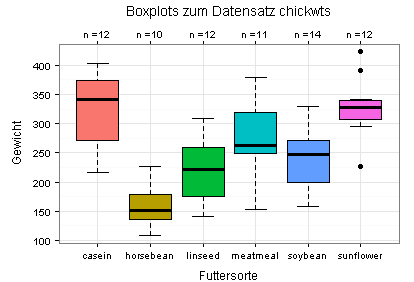
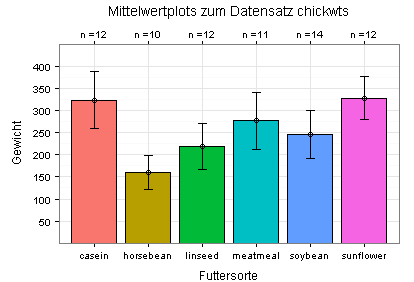
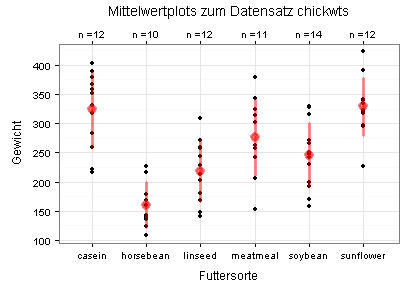
Die Mittelwerte und Standardabweichungen sehen Sie in den folgenden beiden Diagrammen. Im zweiten Diagramm (Stripchart) sehen Sie zusätzlich die Daten (schwarze Punkte; einige davon liegen übereinander).
Ich beginne mit einem zweiseitigen Test auf Mittelwertunterschiede für den Fall der Varianzgleichheit bei unabhängigen Stichproben:
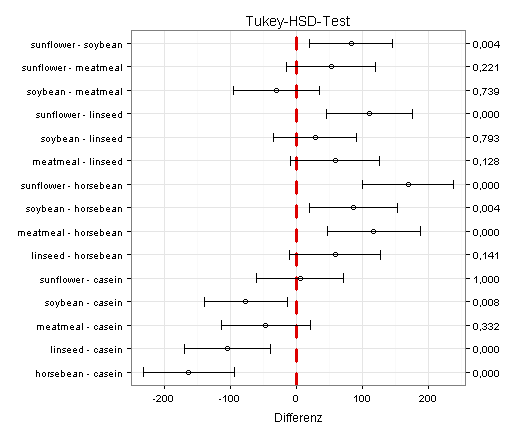
Sie sehen im obigen Diagramm, dass der Test acht signifikante Mittelwertunterschiede ergeben hat (rechte Achse, acht p-Werte kleiner als 0,05). Außerdem sehen Sie die zugehörigen 0,95-Konfidenzintervalle, unter anderem das 0,95-Konfidenzintervall für die Größe »Mittelwert des Gewichts bei Futterzusatz sunflower minus Mittelwert des Gewichts bei Futterzusatz soybean«, das rechts neben der Nulllinie liegt.
Ich wiederhole den Tukey-HSD-Test für den Fall ungleicher Varianzen und erhalte jetzt neun signifikante Mittelwertunterschiede:
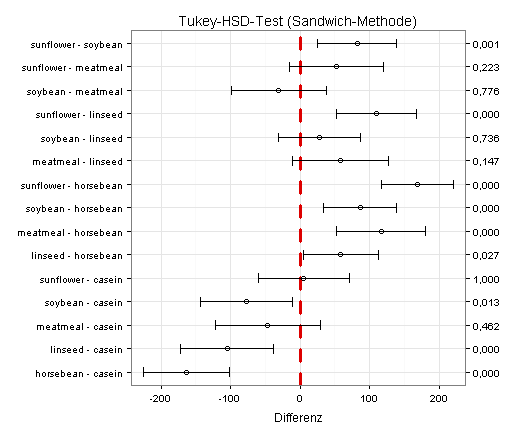
(Einzelheiten zu dieser Methode finden sich unter anderem in Brian S. Everitt und Torsten Hothorn: Statistical Analyses Using R, 2. Auflage, Boca Raton, Florida, 2010, Seite 260.)
Ich vergleiche jetzt die Mediane mit der Funktion pairwise.wilcox.test(), die zur Grundversion von R gehört. Ich erhalte auf diese Weise acht signifikante Unterschiede (jeweils grün markiert):
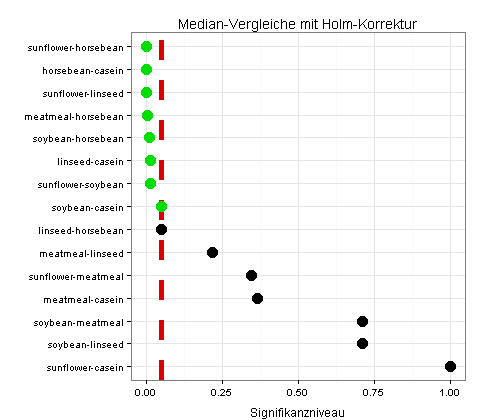
Wegen der wenigen Beobachtungswerte verwende ich zusätzlich eine konservative Methode aus dem Package asbio, die für meine Daten nur fünf signifikante Unterschiede liefert:
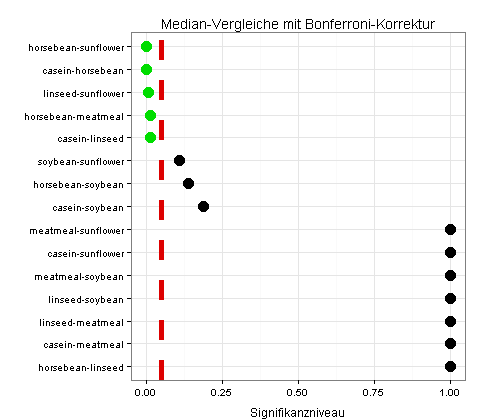
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Diagnoseplots für multivariate Daten
Sie sehen im folgenden Diagramm eine Zusammenfassung des Datensatzes Cars93, der zur Standardinstallation von R gehört:
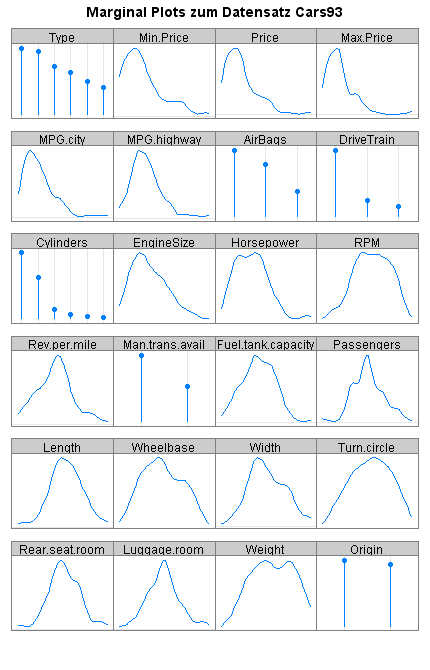
Das Diagramm enthält für jede numerische Variable eine Dichtefunktion. Sie sehen zum Beispiel in der ersten Reihe, dass die weitaus meisten Beobachtungswerte für die Variablen Min.Price, Price und Max.Price auf der jeweiligen x-Achse links liegen und daher relativ klein sind.
Für Faktoren zeigt das Diagramm die Häufigkeiten der Kategorien. Demnach hat die Variable Type (erste Reihe links) sechs Kategorien, die unterschiedlich stark im Datensatz Cars93 vertreten sind.
Im nächsten Diagramm sehen Sie Boxplots für die numerischen Variablen des Datensatzes Cars93:
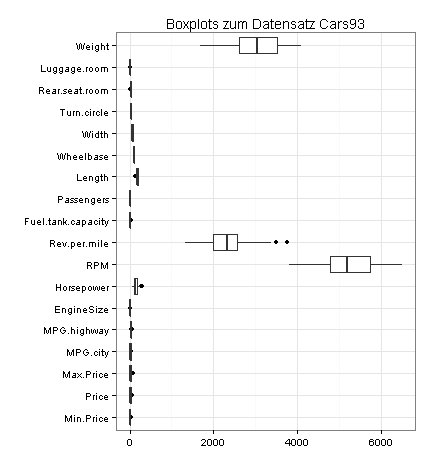
In den Beobachtungswerten zu Rev.per.mile befinden sich demnach zwei Ausreißer (die beiden Punkte).
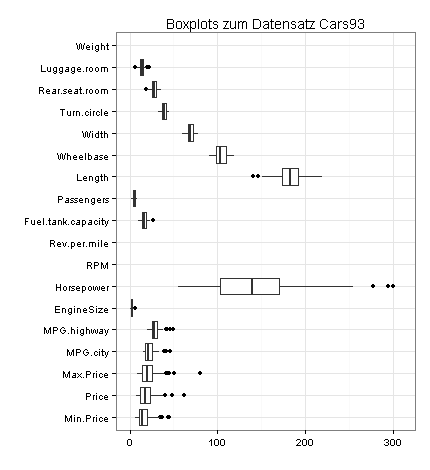
Weil die meisten Variablen relativ niedrige Werte haben, erstelle ich zusätzlich einen vergrößerten Ausschnitt des obigen Diagramms. Auf diese Weise finde ich weitere Ausreißer:
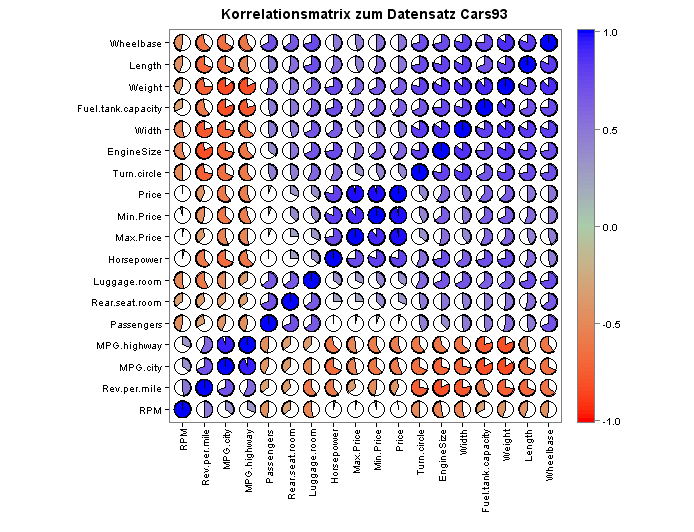
Es folgt ein überblick über die Pearson-Korrelationskoeffizienten aller numerischen Variablenpaare meines Datensatzes:
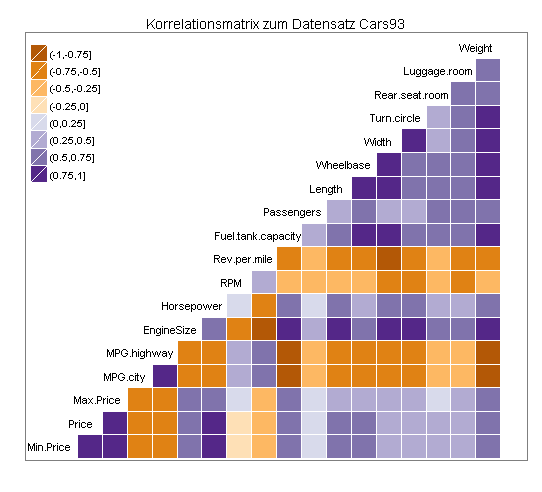
Eine besonders übersichtliche Darstellung meiner Korrelationsmatrix bietet die folgende Grafik:
Für Datensätze mit relativ wenigen Variablen kommen auch andere Darstellungsformen infrage, die ich anhand des Datensatzes Attitude erläutern werde (Attitude gehört zur Standardinstallation von R).
Sie sehen zunächst für alle sieben Variablen dieses Datensatzes Boxplots, in die ich zusätzlich die Mittelwerte eingetragen habe (als Kreuze):
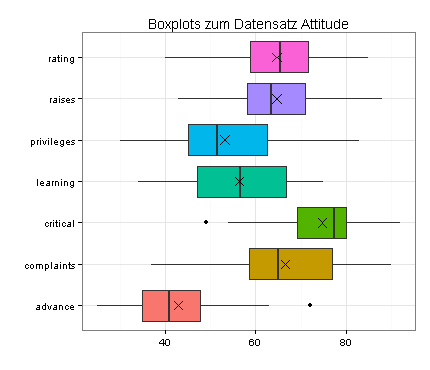
Demnach enthalten die Daten (mindestens) zwei Ausreißer, zu sehen als Punkte in den Boxplots für die Variablen critical und advance.
Außerdem sind mehrere Verteilungen schief, insbesondere die Verteilungen von critical, complaints und advance. Ein möglicher Ausweg wäre eine Transformation der betreffenden Variablen.
Zur Suche nach Ausreißern dienen auch Parallelkoordinatenplots und Andrews-Kurven:
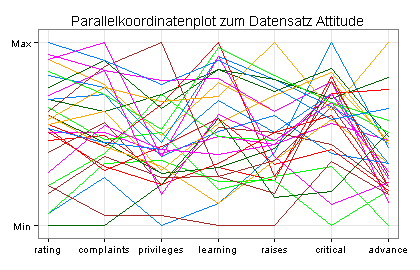
Auffällig ist hier die braune Linie, die zwischen learning und raises auf der Höhe y = Min waagerecht verläuft. Die durch diese Linie beschriebene Beobachtung könnte ein Ausreißer sein.
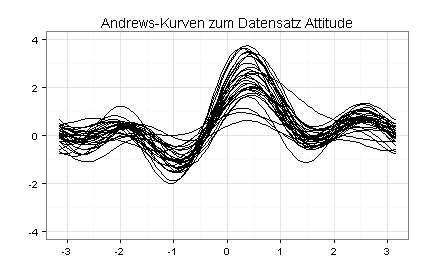
Der Verlauf von Andrews-Kurven wird im Wesentlichen von den ersten fünf Variablen bestimmt. Weil mein Datensatz sieben Variablen enthält, habe ich meine Andrews-Kurven noch einmal gezeichnet, jetzt auf Basis des Datensatzes Attitude mit vertauschten Spalten (Spalte eins als Spalte sieben, Spalte zwei als Spalte sechs usw.):
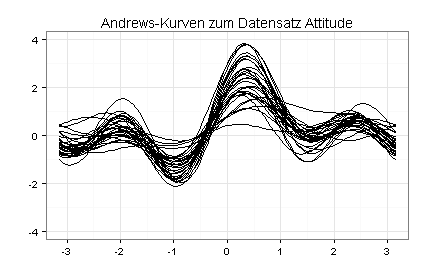
Ausreißer haben aus dem Rahmen fallende Andrews-Kurven. Auffällig ist insbesondere die Andrews-Kurve, die im zweiten Diagramm an der Stelle x = 0 am tiefsten liegt.
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Diagramme zur Hauptkomponentenanalyse
Bei einem in mehreren Lehrbüchern beschriebenen Experiment wurden 48 Bewerber anhand von 15 Kriterien bewertet, jeweils auf einer Skala von null bis zehn.
Ich möchte aus den 15 Kriterien eine kleine Anzahl neuer Kriterien gewinnen, die den Vergleich der Bewerber erleichtern sollen. Hierbei nehme ich an, dass die Anzahl der neuen Kriterien (der latenten Variablen) offen ist.
Nachdem ich meine Hauptkomponentenanalyse durchgeführt habe, muss ich überlegen, wie viele latente Variablen ich haben will.
Gemäß Scree-Plot kommen zwei bis vier latente Variablen (Hauptkomponenten) infrage:
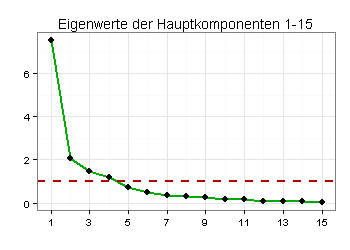
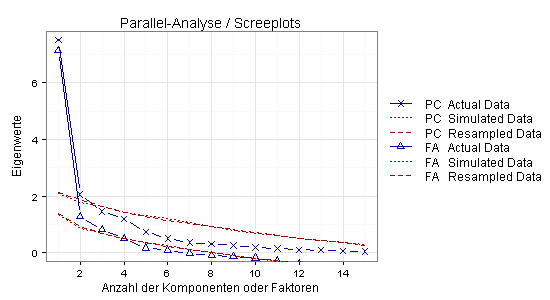
Gemäß Parallel-Analyse sind zwei Hauptkomponenten oder vier Faktoren sinnvoll, das heißt zwei oder vier latente Variablen:
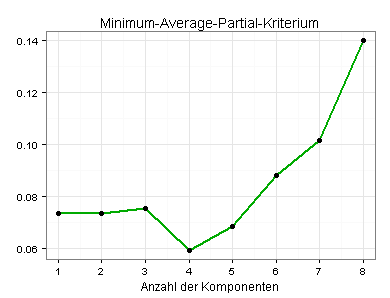
Nach dem MAP-Kriterium sind vier latente Variablen optimal:
Nach den verwendeten Kriterien kommen Einteilungen mit zwei, drei oder vier latenten Variablen infrage. Ich habe daher die Aufgabe, die drei Einteilungen im Hinblick auf ihre inhaltliche Plausibilität zu prüfen.
Sie sehen das Ergebnis im folgenden Diagramm:
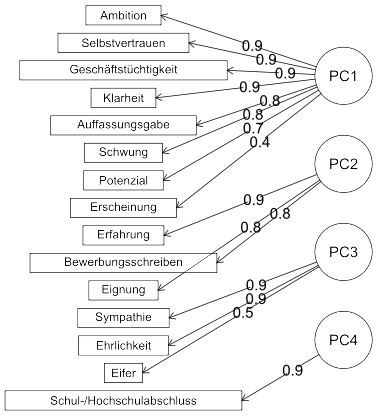
Das Diagramm zeigt links die 15 Kriterien und rechts die vier latenten Variablen. Die Zahlen auf den Pfeilen sind die zugehörigen Ladungen (mit Varimax-Rotation berechnet).
Die vier latenten Variablen sind gut interpretierbar:
- PC1: Softskills
- PC2: Fachkompetenz
- PC3: Sozialkompetenz
- PC4: Ausbildung
Ich interessiere mich zum Beispiel für die Softskills und die Sozialkompetenz der Bewerber:
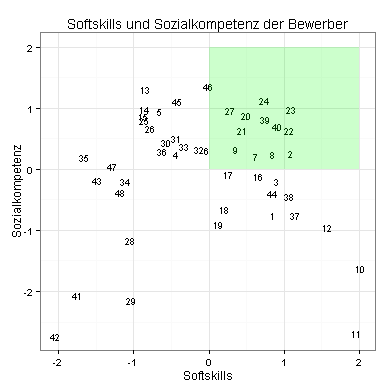
Die Bewerber im grün gefärbten Bereich haben stark ausgeprägte Softskills in Verbindung mit stark ausgeprägter Sozialkompetenz. Besonders interessant ist Bewerber 23.
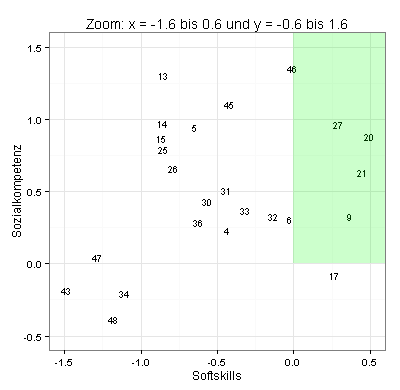
Weil mehrere Komponentenscores dicht beieinander liegen, habe ich die obige Grafik durch einen stark vergrößerten Ausschnitt ergänzt. Sie sehen jetzt, wo die Bewerber 15, 25, 32 und 6 liegen:
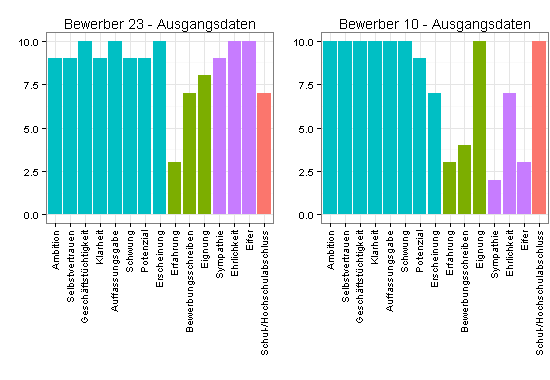
Ich vergleiche zum Beispiel Bewerber 23 mit Bewerber 10, der bessere Softskills hat, aber nur wenig Sozialkompetenz.
Zunächst die ursprünglichen Bewertungen:
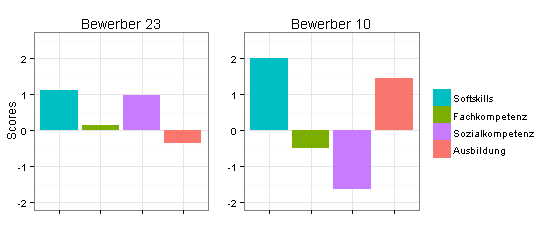
Jetzt die Komponentenscores, die einen sehr viel besseren Vergleich der beiden Bewerber ermöglichen:
Einen Anhaltspunkt für die Güte der gefundenen Einteilung mit vier latenten Variablen erhalten Sie unter anderem durch eine explorative Faktoranalyse. Sie sehen das Ergebnis in der folgenden Tabelle, in die ich nur Ladungen aufgenommen habe, deren Betrag mindestens gleich 0,4 ist:
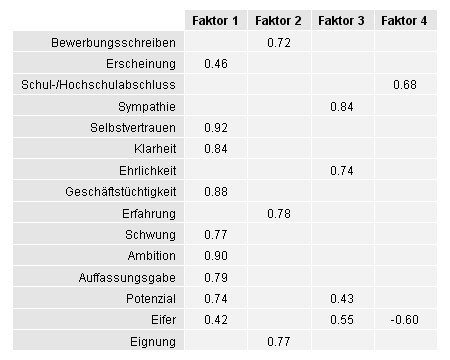
Nach der obigen Hauptkomponentenanalyse werden Sympathie, Ehrlichkeit und Eifer zu einer latenten Variablen zusammengefasst (in der Tabelle als Faktor 3 bezeichnet).
Gemäß Tabelle lädt Eifer auch stark negativ auf Faktor 4 und deutlich positiv auf Faktor 1. Die zu Faktor 1 gehörende Variable Potenzial lädt ebenfalls deutlich positiv auf Faktor 3.
Es wäre demnach sinnvoll, die gefundene Einteilung mit vier latenten Variablen anhand weiterer Daten zu prüfen.
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Grafiken zur Clusteranalyse
Dendrogramme
Die folgenden vier Dendrogramme zeigen, wie Clustereinteilungen durch farbige Linien oder farbige Schrift markiert werden können. Ich habe in allen vier Fällen mit einem agglomerativen Verfahren gearbeitet. Die Dendrogramme sind daher von unten nach oben oder - zweites Diagramm - von rechts nach links zu lesen.
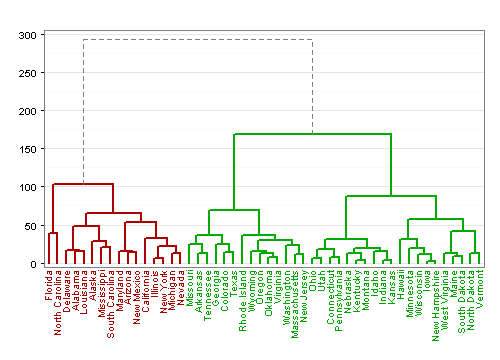
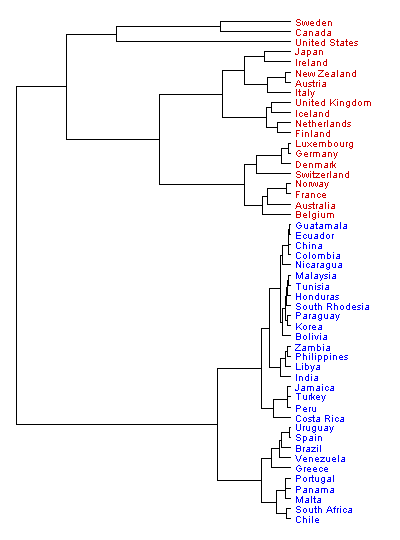
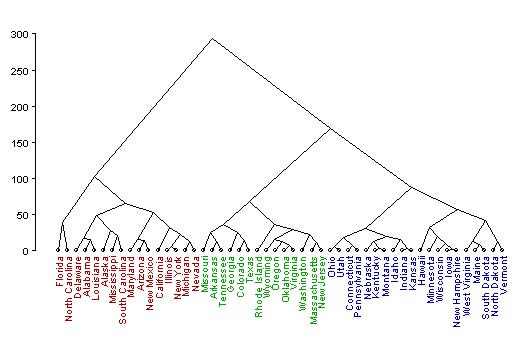
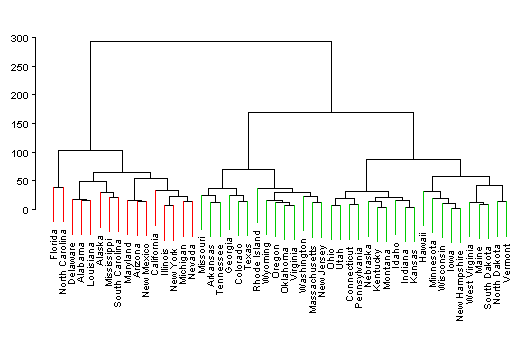
Anwendungsbeispiel
Für das folgende Anwendungsbeispiel verwende ich einen Datensatz mit 200 Beobachtungen für fünf metrische Variablen, die zum Teil auf unterschiedlichen Skalen gemessen wurden. Meine Daten eignen sich gut für eine Clusteranalyse, weil die fünf Variablen jeweils nur wenig korreliert sind.
Die wenigen Ausreißer in meinen Daten deute ich als extreme Beobachtungswerte (und nicht als Datenfehler). Ich belasse die Ausreißer daher in meinem Datensatz.
Ich versuche zunächst, meine Daten in möglichst gleichgroße homogene Gruppen einzuteilen.
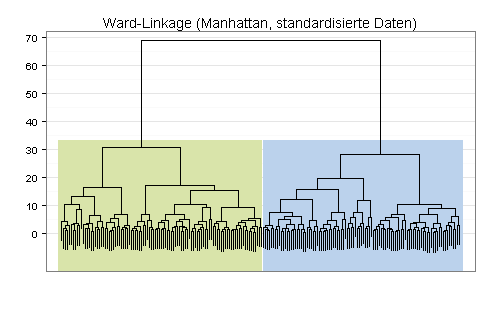
Hierzu verwende ich das Ward-Linkage-Verfahren - wegen der unterschiedlichen Skalen mit vorheriger Standardisierung und wegen der Ausreißer mit Manhattan-Distanz.
Bei dieser Einstellung erhalte ich einen Agglomerativen Koeffizienten in Höhe von 0,976. Die Daten sind demnach sehr gut für das Ward-Linkage-Verfahren geeignet.
Aufgrund des Dendogramms halte ich eine Einteilung in zwei oder vier Cluster für erwägenswert:
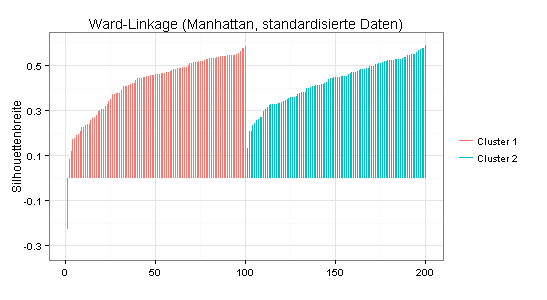
Der Silhouetten-Plot für die obige Zwei-Cluster-Lösung macht einen relativ guten Eindruck (durchschnittliche Silhouettenbreite = 0,42). Allerdings haben einige Beobachtungswerte eine sehr geringe oder negative Silhouettenbreite, was darauf hindeutet, dass die Trennung zwischen den beiden Clustern unscharf ist. Es wäre daher zu überlegen, ob die Zusammensetzung der beiden Cluster inhaltlich sinnvoll ist.
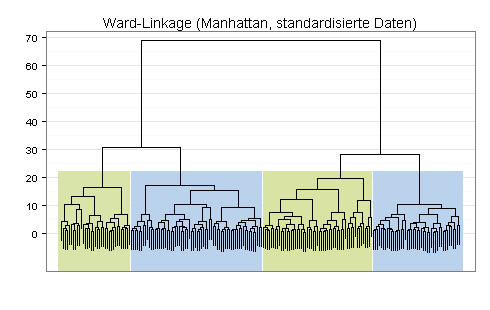
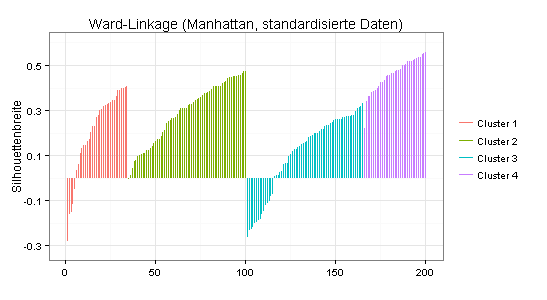
Zum Vergleich der Silhouetten-Plot für die mit dem Ward-Linkage-Verfahren gefundene Vier-Cluster-Lösung (durchschnittliche Silhouettenbreite = 0,25):
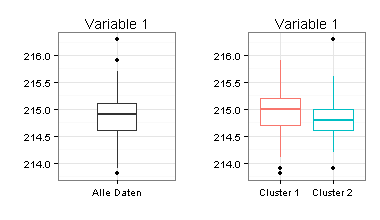
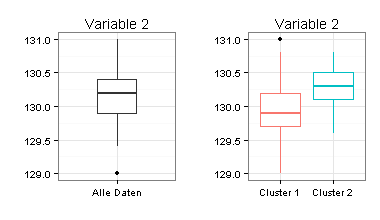
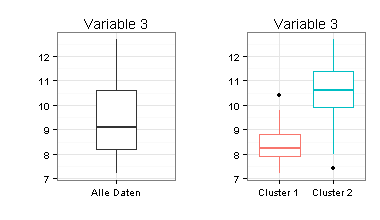
Ich habe für die Zwei-Cluster-Lösung Boxplots erstellt. Sie sehen daran, dass sich die beiden Cluster nur schwer voneinander trennen lassen (besonders für Variable 1) und dass Mittelwertvergleiche zwischen den beiden Clustern fragwürdig wären.
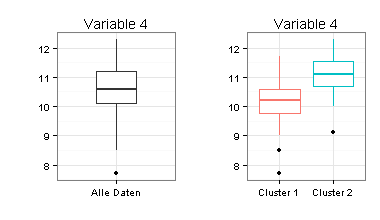
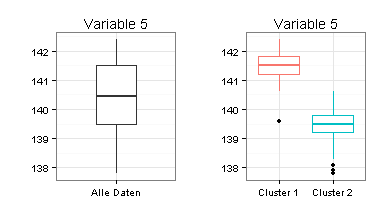
Ich versuche daher ein anderes Verfahren: Mclust.
Mclust bestimmt die Clusterzahl anhand des BIC (Bayesian Information Criterion) und erfordert keine Festlegung des Distanzmaßes.
Mclust setzt voraus, dass die zu clusternden Daten multivariat normalverteilt sind. Betrachten Sie dazu den folgenden Diagnoseplot, der meine 200 Beobachtungswerte enthält:
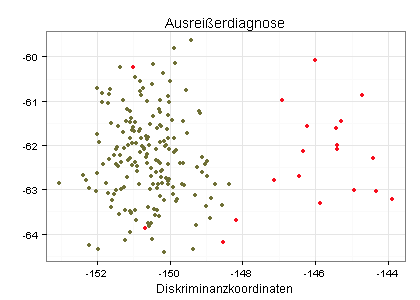
Ich habe meine Beobachtungswerte mit Hilfe der Funktion uni.plot() aus dem Package mvoutlier in zwei Gruppen unterteilt: Beobachtungswerte, die einer multivariat normalverteilten Grundgesamtheit entstammen (olivgrün) und Beobachtungswerte, die einer anderen Grundgesamtheit entstammen (rot). Ich könnte daher prüfen, ob ich die rot markierten Beobachtungswerte aus meiner Clusteranalyse ausklammern sollte.
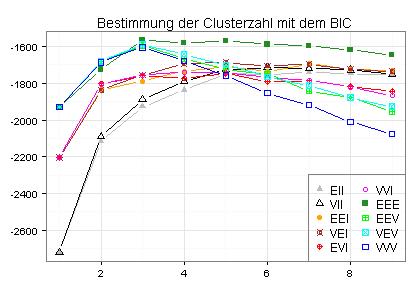
Der folgende Plot zeigt, dass nach dem Mclust-Verfahren drei Cluster optimal sind (wenn ich, im Einklang mit der Mclust-Dokumentation, auf eine vorherige Standardisierung meiner Daten verzichte):
Sie sehen anhand der von mir ausgewählten Koordinaten-Projektionsplots, dass sich die gefundenen drei Cluster zum Teil überschneiden:
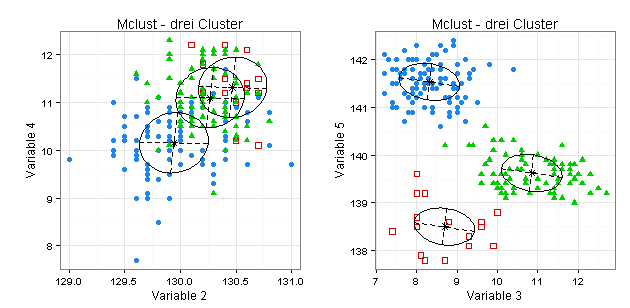
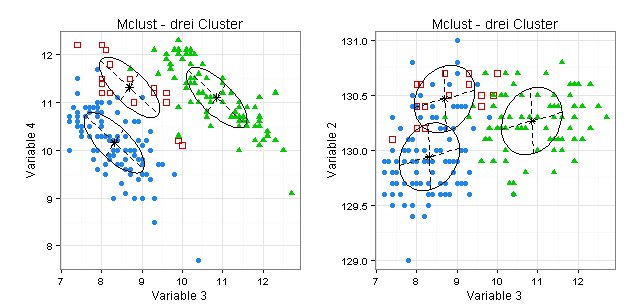
Validierung
Im letzten Abschnitt ist offen geblieben, ob ich meine Daten in zwei oder drei Cluster einteilen sollte.
Eine überzeugende Antwort auf diese Frage ist nur möglich, wenn auch inhaltliche überlegungen in die Validierung einfließen. Denkbar wäre zum Beispiel, dass drei Cluster sinnvoller sind als zwei, weil die Einteilung in drei Gruppen sehr gut interpretierbar ist.
Statistische Hilfsmittel wie Kennzahlen und zweidimensionale Darstellungen der infrage kommenden Clustereinteilungen können dabei helfen, eine aus inhaltlichen Gründen sinnvolle Clustereinteilung zu untermauern.
Ich beginne mit den Kennzahlen, die ich alle doppelt berechne, einmal auf Basis der Originaldaten (links) und einmal auf Basis der standardisierten Daten (rechts).
Nach dem Kriterium der Konnektivität sind zwei Cluster optimal:
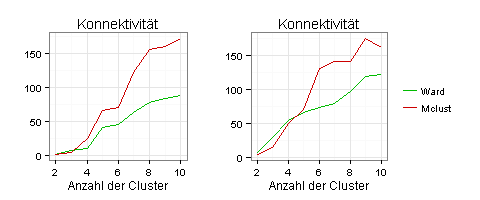
Nach dem Dunn-Index sind drei Cluster optimal:
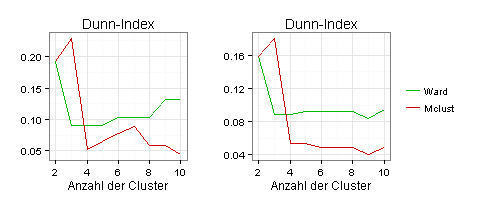
Nach dem Kriterium der Silhouetten-Breite sind zwei Cluster optimal:
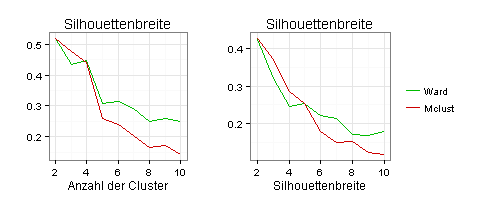
Als Stabilitätskriterium habe ich hier nur die Average Proportion of Non-overlap (APN) verwendet, weil andere Stabilitätskennzahlen für meine Daten nichts hergeben.
Das Kriterium der APN spricht für zwei Cluster:
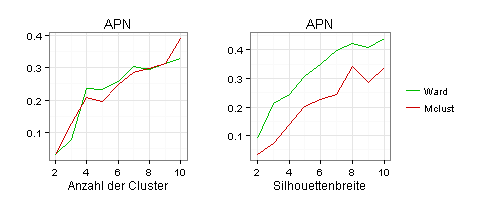
Ich komme jetzt zur grafischen Darstellung der infrage kommenden Clustereinteilungen. Dies ist schwer, weil meine Daten fünfdimensional sind (fünf Variablen).
Die klassische Variante sind Scatterplots mit Diskriminanzkoordinaten:
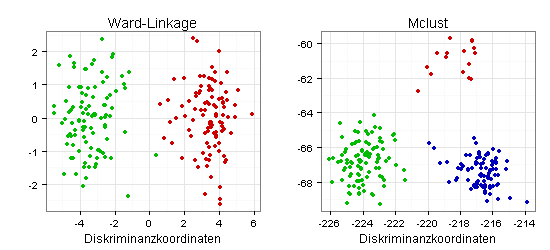
Im linken Diagramm wirkt die Trennung der beiden Cluster wenig gelungen, weil ein grüner Punkt sehr dicht bei Cluster zwei liegt. Das rechte Diagramm (drei Cluster) macht auf mich einen besseren Eindruck.
Die beiden Scatterplots mit Koordinaten nach Hastie und Tibshirani liefern ein ähnliches Bild (im linken Diagramm wirkt ein grüner Punkt deplatziert):
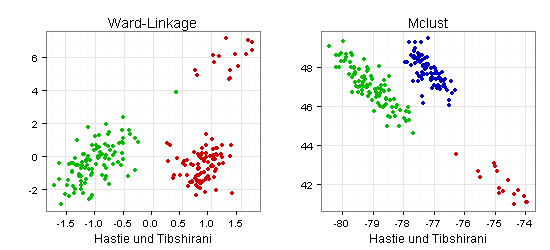
Die in den folgenden zwei Scatterplots verwendeten Koordinaten stammen vom Entwickler des R-Packages fpc, mit dem ich meine Scatterplots zur Cluster-Validierung erstellt habe:
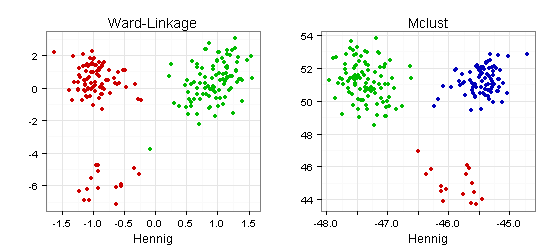
Auch hier macht die mit Mclust gefundene Drei-Cluster-Lösung auf mich einen besseren Eindruck.
Eine völlig andere Einschätzung ergibt sich mit Koordinaten nach Young, Marco und Odell:
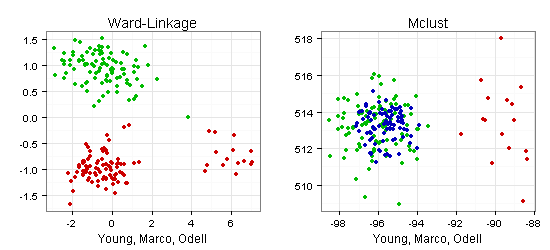
Nach dem rechten Scatterplot wirkt die Drei-Cluster-Lösung missraten. Im linken Scatterplot wäre dagegen eine Einteilung in drei Cluster naheliegend (links oben, links unten, rechts).
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Grafiken zur Diskriminanzanalyse
Ich verwende wieder meine Daten zur Clusteranalyse (200 Beobachtungswerte für fünf metrische Variablen), die ich durch das Ziehen einer Stichprobe in eine Trainingsgruppe und in eine Testgruppe einteile.
Ich will meine Diskriminanzanalyse mit der Trainingsgruppe durchführen und auf dieser Basis die Clusterzugehörigkeit der Testgruppe prognostizieren, einmal für die Zwei-Cluster-Lösung mit Ward-Linkage und einmal für die Drei-Cluster-Lösung mit Mclust.
Weil die Trainingsgruppe relativ klein ist (100 Beobachtungswerte), erscheint mir die Quadratische Diskriminanzanalyse sinnvoll. Allerdings kommen auch andere Verfahren infrage.
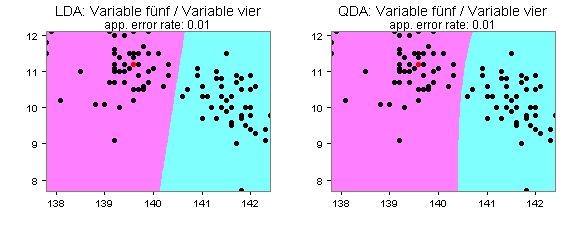
Die folgenden Partitionsplots deuten darauf hin, dass die Quadratische Diskriminanzanalyse für meine Daten besser geeignet ist als die häufig verwendete Lineare Diskriminanzanalyse:
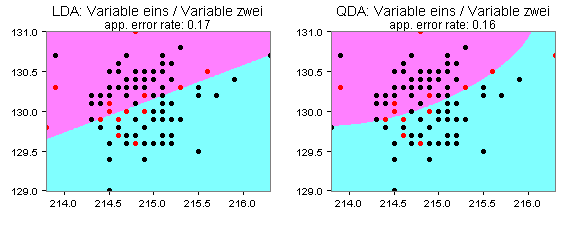
Für die Variablen eins und zwei mit zwei Clustern (Ward-Linkage) ergibt sich demnach für die Quadratische Diskriminanzanalyse eine geringere Apparent Error Rate als für die Lineare Diskriminanzanalyse. Die beiden Flächen stehen hier für die beiden Cluster und die rot gefärbten Punkte für Klassifikationsfehler.
Für die Variablen eins und zwei mit drei Clustern (MClust) ergibt sich ein ähnliches Bild:
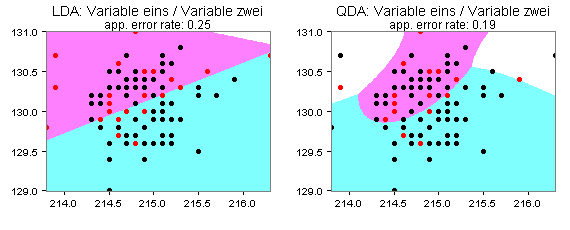
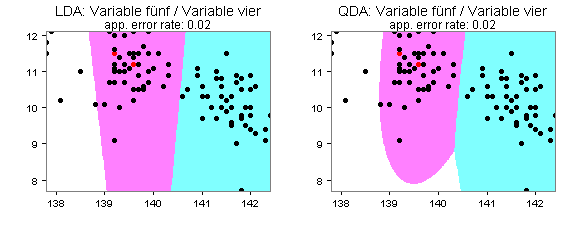
Die Quadratische Diskriminanzanalyse muss allerdings für meine Daten nicht immer zu besseren Prognosen führen als die Lineare. Sie sehen dies an den folgenden vier Partitionsplots für die Variablen vier und fünf:
Ich prognostiziere jetzt die Clusterzugehörigkeit für die 100 Beobachtungswerte meiner Testgruppe mit der Quadratischen Diskriminanzanalyse, für die in R unter anderem die Funktionen qda() und QdaClassic() zur Verfügung stehen (Packages MASS und rrcov).
Sie sehen die Ergebnisse in den folgenden beiden Diagrammen:
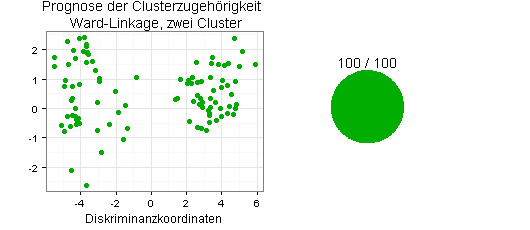
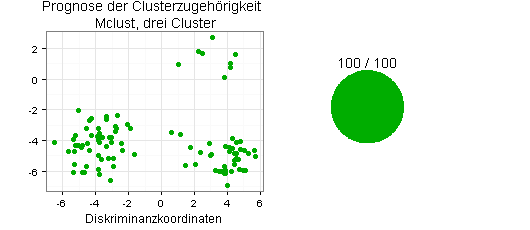
Beide Ergebnisse - jeweils 100 von 100 Beobachtungswerten richtig zugeordnet - sind ungewöhnlich gut, was Zufall sein kann oder nicht. Interessant wäre daher die Frage, wie das Ergebnis aussieht, wenn ich die Stichprobenziehung mehrmals wiederhole und die durchschnittlichen Erfolgsquoten berechne.
Starken Einfluss auf die Prognosen haben auch die gewählten Einstellungen. Bei der Quadratischen Diskriminanzanalyse betrifft dies insbesondere die A-priori-Wahrscheinlichkeiten der Gruppenzugehörigkeit. Außerdem können Sie eine robuste Variante wählen.
Zum Vergleich verwende ich ein völlig anderes Verfahren - RPART (Rekursive Partitionierung, Klassifikationsbäume).
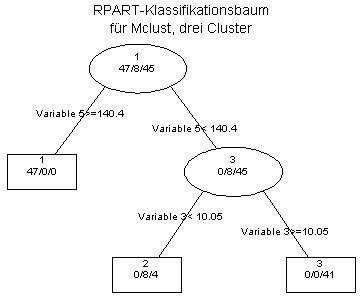
RPART ist vor allem interessant, wenn Ihre Daten gemischt skaliert sind und/oder in Ihren Daten viele Angaben fehlen.
RPART liefert die folgenden Ergebnisse:
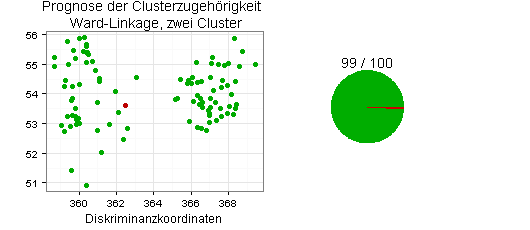
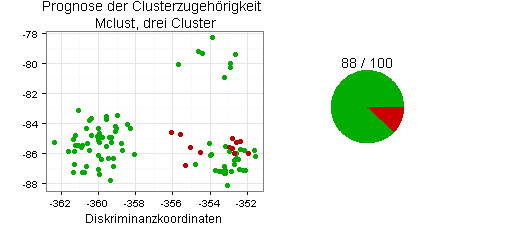
RPART hat demnach die Clusterzugehörigkeit nach Ward-Linkage (zwei Cluster) sehr viel besser vorhersagt als die Clusterzugehörigkeit nach Mclust (drei Cluster).
Zurück zum Seitenanfang
Zur Seite Statistik-Service
Strukturgleichungsmodellierung
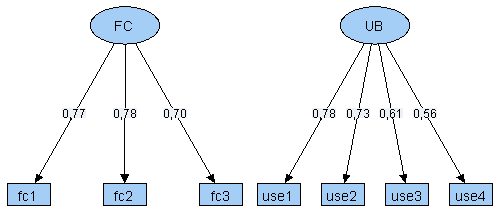
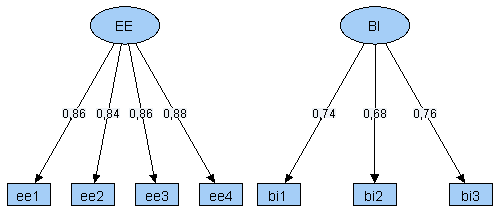
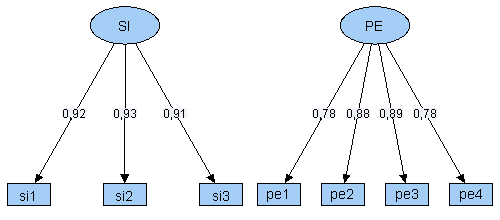
Das folgende Pfaddiagramm zeigt eine vereinfachte Version eines Modells von Venkatesh aus der Zeitschrift MIS Quarterly (Jahrgang 27, 2003, Nr. 3, S. 425-478). Die berufliche Computernutzung (Use Behavior) wird in dieser Modellversion von fünf latenten Variablen beeinflusst:
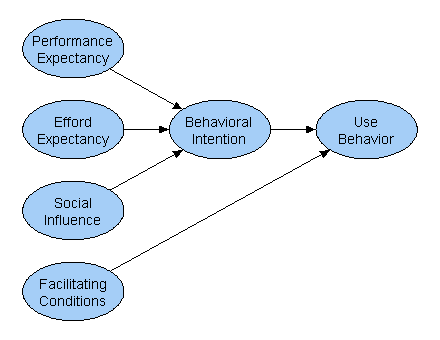
Alle im Modell enthaltenen latenten Variablen wurden anhand von Indikatoren operationalisiert. Für den Faktor Efford Expectancy (EE) sind dies:
- ee1 - My interactions with computers are clear and understandable
- ee2 - It is easy for me to become skillful using computers
- ee3 - I find computers easy to use
- ee4 - Learning to use computers is easy for me
Für die Indikatorvariablen, für die jeweils 300 Beobachtungswerte berücksichtigt wurden, ergeben sich die folgenden empirischen Dichtefunktionen:
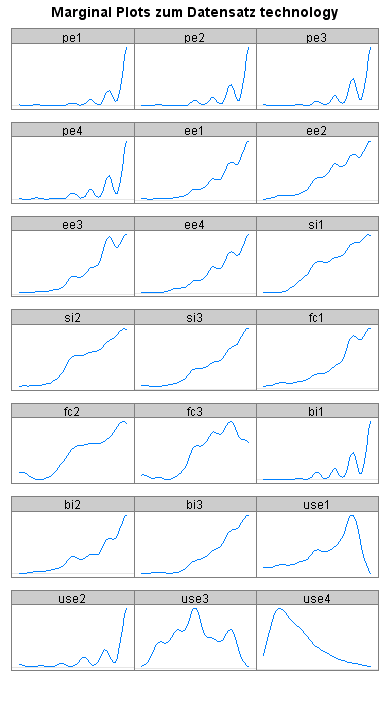
Meine Daten sind vermutlich nicht multivariat normalverteilt (die Marginal Plots sind fast alle nicht glockenförmig). Ein Shapiro-Wilk-Test auf multivariate Normalverteilung bestätigt diese Einschätzung (p=0,000).
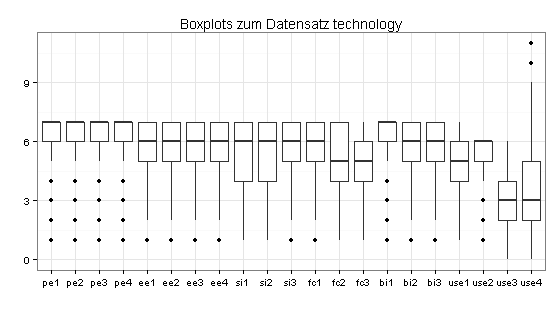
Die Boxplots zu den Indikatorverteilungen deuten darauf hin, dass der Datensatz Ausreißer enthält:
Ich untersuche die Daten daher mit dem LOF-Verfahren (Local Outlier Factor) und erhalte die folgende Dichtefunktion:
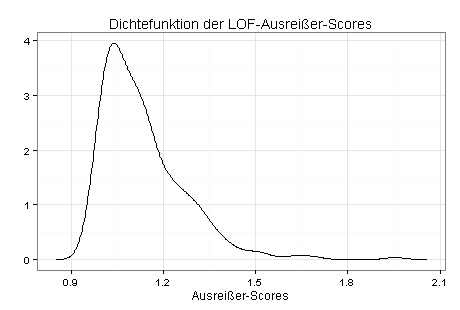
Besonders auffällig ist Fragebogen 292 (Ausreißer-Score = 1,95), der auf fehlerhafte oder unsinnige Angaben untersucht werden sollte. Hohe Ausreißer-Scores haben auch die Fragbögen 82, 124 und 256.
| Score | Fragebogen | |
|---|---|---|
| 1 | 1.953726 | 292 |
| 2 | 1.691512 | 82 |
| 3 | 1.647254 | 124 |
| 4 | 1.607686 | 256 |
| 5 | 1.524096 | 103 |
| 6 | 1.521639 | 251 |
| 7 | 1.498418 | 36 |
| 8 | 1.474248 | 289 |
| 9 | 1.445468 | 207 |
| 10 | 1.435374 | 240 |
Ich verwende bei meinen folgenden Auswertungen die unbereinigten Daten (alle 300 Beobachtungswerte).
Der nächste Schritt besteht in einer explorativen Faktoranalyse, bei der die gefundenen Cross-Loadings interessieren. Neben dem Maximum-Likelihood-Verfahren verwende ich auch das Minimum-Residual-Verfahren, das keine normalverteilten Daten voraussetzt.
Die Ergebnisse sind in den folgenden beiden Netzwerk-Diagrammen zusammengefasst. Grüne Pfeile stehen hier für positive Loadings, rote Pfeile für negative. Je dicker der Pfeil, desto höher der Absolutwert.
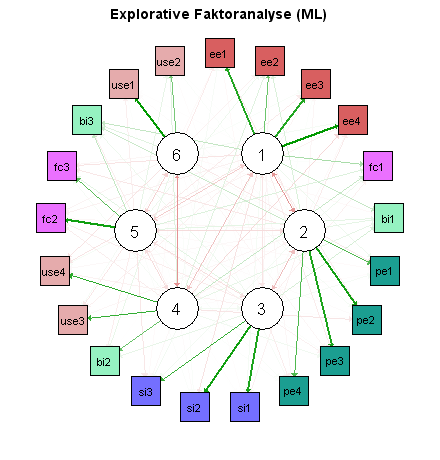
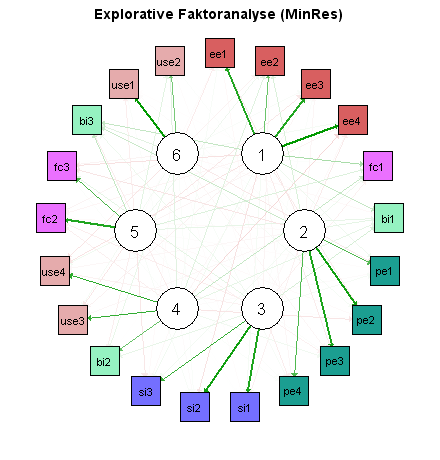
Beide Verfahren haben zu ähnlichen Ergebnissen geführt. Besonders ungünstig ist hier, dass die Indikatoren bi1, bi2 und bi3 (hellgrün) bei der explorativen Faktoranalyse drei verschiedenen Faktoren zugeordnet werden.
Für die jetzt folgende konfirmatorische Faktoranalyse habe ich wegen der vermutlich nicht-normalverteilten Daten zwei Schätzverfahren gewählt.
Beide Schätzverfahren liefern für meine Daten ähnliche Ergebnisse. Trotzdem ist die Variante mit Diagonally Weighted Least Squares hier weitaus besser (RMSEA mit ML = 0,074 [0,066; 0,082], RMSEA mit DWLS = 0,017 [0,000; 0,032], in eckigen Klammern die 0,90-Konfidenzintervalle).
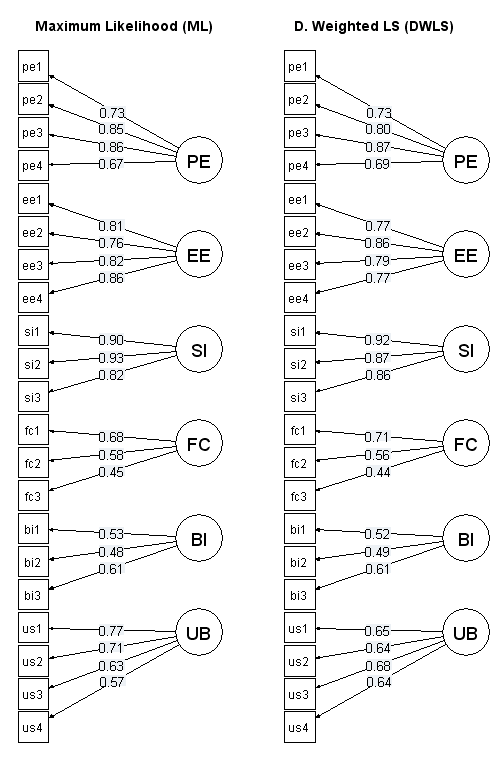
In beiden Modellvarianten sind die standardisierten Loadings von BI und FC auffallend klein. Kennzahlen wie Cronbachs's Alpha, die Faktorreliabilität, die Durchschnittlich Erfasste Varianz sowie das Fornell/Larcker-Kriterium zeigen für beide Modelle, dass die Faktoren BI und FC schlecht operationalisiert sind.
Interessant ist auch ein Vergleich der empirischen Korrelationen mit den vom Modell implizierten Korrelationen (hier am Beispiel der ML-Schätzung):
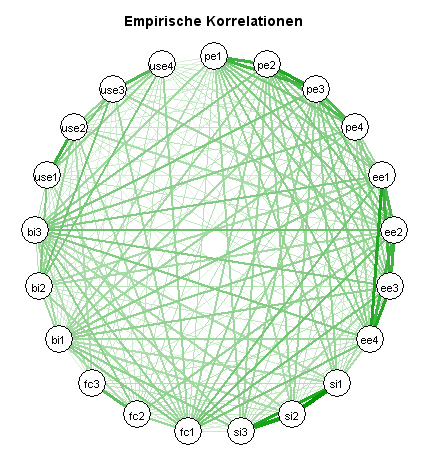
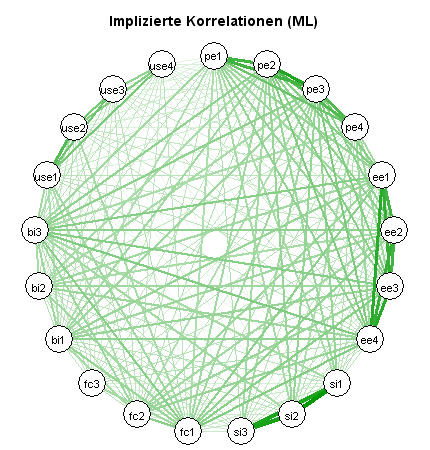
Beide Netzwerkdiagramme weichen deutlich voneinander ab.
Die geschilderten Ergebnisse legen nahe, die verwendeten Daten zu bereinigen, Indikatoren zu streichen oder neue Variablen in das Modell aufzunehmen.
Ich verzichte auf diese Schritte und schätze mein Modell einmal als LISREL-Modell mit der Maximum-Likelihood-Methode und einmal mit Partial Least Squares:
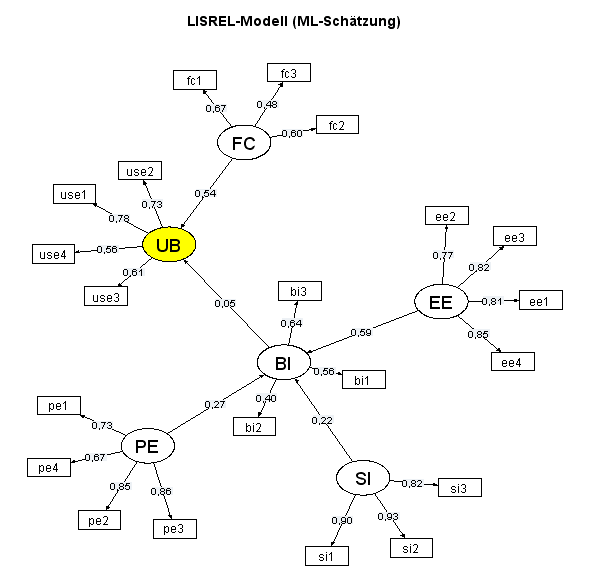
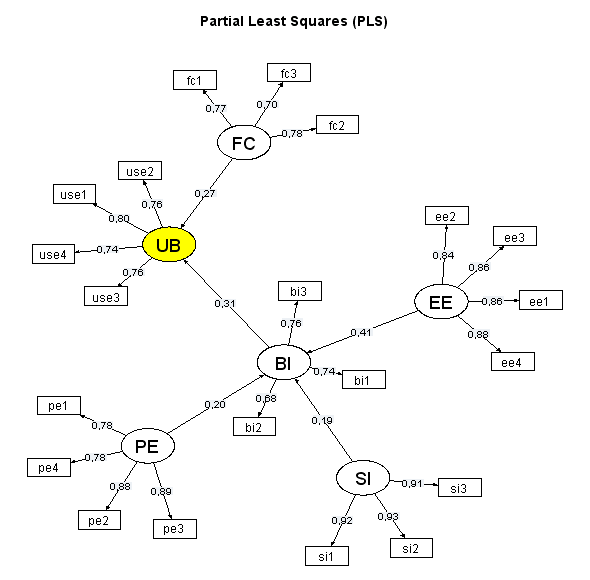
Der auffälligste Unterschied zwischen beiden Pfaddiagrammen besteht im Schätzwert für den Pfadkoeffizienten UB~BI (0,05 im LISREL-Modell und 0,31 mit Partial Least Squares).
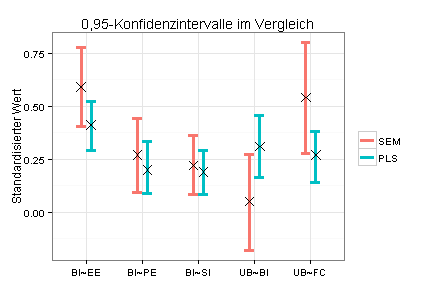
Das folgende Diagramm zeigt sämtliche Pfadkoeffizienten (als Kreuze dargestellt) mit 0,95-Konfidenzintervallen. Hier fällt auf, dass die für das LISREL-Modell ermittelten Konfidenzintervalle (rot) generell sehr groß sind und dass der Pfadkoeffizient UB~BI im LISREL-Modell nicht signifikant ist (0 im 0,95-Konfidenzintervall). Ich habe die Konfidenzintervalle für das PLS-Modell durch Bootstrapping ermittelt.
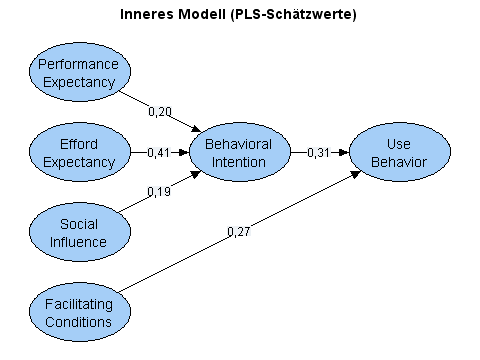
Zum Abschluss zeige ich die Pfadkoeffizienten und Loadings des PLS-Modells noch einmal:
![]()
Internetseiten
Fachbeiträge
Das liberale Propaganda-Handbuch, Taschenbuch, 382 Seiten
Einführung in die Statistik-Software R Commander
Business Cases für den Verkauf
Fachliteratur suchen mit Google Scholar, WorldCat etc. pp.
Ghostwriter für Dissertationen, Bachelor- und Masterarbeiten
Wissenschaftliches Ghostwriting
Content-Marketing mit White Papers für Start-up-Unternehmen im B2B-Geschäft
1. White Papers als Werbemittel
2. Fallstudien im Sinne von White Papers
Warum White Papers im B2B-Geschäft häufig wirkungsvoller sind als klassische Werbung
Lead-Management im B2B-Geschäft - warum und wie?
White Papers erstellen - von der Themenwahl bis zum Layout